RuneLM: The Standalone DSP for Retention-Aware LLM Routing
Vendor retention is now runtime input. RuneLM is the standalone Data Sanitization Proxy that classifies, pseudonymizes, routes, rehydrates, and audits outbound LLM calls before sensitive context reaches a provider.

The lesson from the Claude Fable 5 retention discussion is not that enterprises should panic about model training.
It is cleaner than that.
Vendor retention is now runtime input.
Anthropic's own API retention documentation puts Claude Fable 5 and Claude Mythos 5 in a separate bucket: both models require 30-day data retention, and Zero Data Retention is not available for them. Anthropic also states that retained API data is not used for model training without express permission. Those two facts can both be true at the same time.
That is exactly why the engineering question changes.
The question is no longer only: "Can this model solve the task?"
The question is:
- What data is inside this request?
- Can this provider retain it?
- Does this route have Zero Data Retention?
- Is prompt caching eligible for this workload?
- Did context compaction remove enough risk, or only reduce token count?
- Is this payload safe for an external model after pseudonymization?
- Should this call stay on L1 local inference?
- If the allowed route is over budget, should the request down-route, wait, or stop?
RuneLM exists for that layer.
It is the standalone Data Sanitization Proxy from BlackUnicorn. Not a dashboard feature. Not an agent platform module. A deployable chokepoint that sits between your application and any LLM provider.
Every outbound LLM call goes through the same enforced sequence:
- Verify caller identity.
- Classify the payload.
- Pseudonymize sensitive entities.
- Route by sensitivity tier.
- Call the allowed model route.
- Rehydrate only placeholders RuneLM created on the way out.
- Write an HMAC-hashed audit event without storing raw prompt text.
If any stage fails, the request is blocked.
Cleartext fallback is not a configuration mistake waiting to happen. It is absent from the design.
Retention Became A Routing Problem
LLM routing used to be a capability problem.
Send easy work to a cheap model. Send hard work to a stronger model. Use prompt caching where available. Compress context when the window gets large. Escalate only when the answer quality needs it.
That is a good cost strategy.
It is incomplete.
The route also has a data-retention posture. A public frontier model, a contracted enterprise model, a local Ollama deployment, a prompt-cache feature, a file API, a batch API, and a managed agent session do not carry the same storage behavior. They cannot be treated as interchangeable endpoints in a router.
Anthropic's API docs are useful here because they show the shape of the problem directly. The Messages API can be eligible for ZDR. Prompt caching is documented as ZDR-eligible, with cache representations and hashes kept only for the cache TTL. Batch processing, Files API, code execution containers, managed agents, and the Fable/Mythos model requirements carry different retention behavior.
That is not a policy footnote.
That is route metadata.
RuneLM turns it into an enforcement point.
What RuneLM Is
RuneLM is a fail-closed middleware for outbound LLM calls.
The shipped proxy exposes OpenAI-compatible and Anthropic-compatible HTTP surfaces, so application code can adopt it by changing the client base URL rather than rewriting every call site.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="sk-dsp-...",
)The install path is intentionally ordinary:
pip install 'dsp-llm[proxy]'
dsp-llm config validate --config dsp.yaml
dsp-llm serve --config dsp.yaml --host 127.0.0.1 --port 8080Under that boring install is the part that matters: the caller does not choose a provider directly. The payload is classified first, then RuneLM decides which provider tier is allowed to see the sanitized request.
The standalone build includes the proxy, dry-run corpus replay, dashboard/config surfaces, rate limiting, tamper-evident audit options, TypeScript/Go/Rust SDKs, a sidecar binary, LiteLLM and LangChain adapters, an OpenAI Agents SDK wrapper, and a Claude Code subagent adapter. The center stays the same across each integration:
classify -> pseudonymize -> route -> call -> rehydrate -> audit.
The adapter changes where RuneLM plugs in.
The guarantee does not change.
The Five Properties That Matter
RuneLM is not a keyword filter around a prompt.
The proxy is built around five load-bearing properties.
- Tiered classification drives routing. LOW, MEDIUM, HIGH, and BLOCKED are not labels for reports. They decide which provider tiers can process the request.
- Pseudonyms are session-scoped and type-preserving. An email becomes an email-shaped placeholder. An internal IP becomes an internal-looking placeholder. The model can reason over structure without seeing the real value.
- Routing is enforced by classification. HIGH routes to L1 local only. MEDIUM can use L1 or a contracted L2 route with the required data posture. LOW can use broader provider routes. BLOCKED never leaves.
- Rehydration is map-bounded. RuneLM reverses only placeholders that exist in the outbound substitution map for that session. If a model fabricates a placeholder-shaped token, it stays masked.
- Audit is hashed, not copied. Prompt and response hashes are HMAC-SHA-256. The audit trail records decisions, classification, route, and metadata without storing the raw sensitive text.
Each property closes a different failure mode.
Classification without routing is advisory.
Pseudonymization without bounded rehydration is injectable.
Audit with raw prompts becomes a second leak.
Routing without caller identity can be tricked by a self-reported header.
Fail-open behavior turns every exception into a data exposure path.
RuneLM treats those as architecture bugs, not edge cases.
The Classifier Is The First Router
RuneLM's classifier is layered because sensitive data rarely arrives in a polite shape.
The current DSP-LLM architecture runs a staged pipeline:
- Unicode normalization. NFKC normalization closes homoglyph and zero-width splitting tricks before matching begins.
- Obfuscation-aware blocklist. The classifier checks raw text plus decoded, folded, and stripped views for operator-defined sensitive terms.
- Custom and built-in regex. Emails, IP ranges, credentials, GitHub tokens, JWTs, PEM keys, LDAP DNs, IBANs, paths, cloud keys, and related patterns are classified before dispatch.
- Structured-data fanout. JSON, XML, CSV, Nmap XML, and Burp-style outputs are parsed so sensitive values hidden in structure still affect the route.
- NER and operator-list matching. Presidio and curated operator lists catch entities that regex alone will not.
- Coreference detection. Phrases like "the client" or "the system in scope" can still escalate the session when the surrounding context is sensitive.
- Per-caller overrides and session escalation. Operators can pin a caller to a stricter floor, and a session only escalates upward.
That last point matters for agents.
An agent may start with public context, retrieve a sensitive memory, then send a short follow-up that looks harmless in isolation. RuneLM does not forget that the session touched sensitive content. Once the session escalates, the route stays constrained.
This is how retention-aware routing survives multi-turn work.
Pseudonymization Is The Middle Path
Blocking every external model is clean on paper and expensive in practice.
Sending raw customer, finance, security, or source-code context to every strong model is fast on paper and dangerous in practice.
RuneLM creates a middle path.
Original:
Summarize Acme Industries' Q3 board memo for cfo@acme.com.
The host at 10.0.4.7 is in scope. Reported revenue was $42M.
Sanitized:
Summarize ORG_a3b7_0101's Q3 board memo for EMAIL_a3b7_0101.
The host at IP_a3b7_0101 is in scope. Reported revenue was AMOUNT_a3b7_0101.The provider sees structure.
The model can reason.
The operator gets the rehydrated answer.
The raw entity stays inside the caller-controlled boundary.
RuneLM stores the substitution map with AES-256-GCM and a session TTL. Closing an engagement deletes the maps and sessions, then records the deletion event. The sensitive value is not scattered across provider logs, application logs, or debugging traces.
Local, Contracted, Public
RuneLM's routing model is deliberately simple:
- L1 local. Local Ollama, vLLM, llama.cpp, LM Studio, or another provider inside the operator boundary. HIGH data stays here.
- L2 contracted. External provider routes that meet the configured contractual posture, including DPA and zero-retention requirements where required. MEDIUM can use this tier after pseudonymization.
- L3 public. Broader external model routes for LOW data.
This model fits cost-aware agentic frameworks.
A budget router can still prefer cheaper inference. A compression layer can still shrink prompts. Prompt caching can still reduce repeated context. A model router can still choose a stronger model when quality requires it.
RuneLM adds the missing constraint:
cost optimization can choose only from routes the data policy permits.
If the L3 route is cheap but the payload is HIGH, RuneLM keeps it on L1.
If a provider has a retention requirement that disqualifies it for MEDIUM customer data, RuneLM can route elsewhere.
If no route satisfies the classification and provider policy, the request stops.
That is what fail-closed means in production. It is not a dramatic button. It is the refusal to turn a budget, latency, or availability problem into a data-loss event.
Dry Run Before You Route
RuneLM also ships a dry-run path.
Operators can replay a prompt corpus through the classifier and routing rules without calling an upstream model, mutating substitution state, or storing prompt text in an audit trail.
That is how teams tune the proxy safely:
- Run real prompt shapes through classification.
- Inspect levels, entity counts, and proposed routes.
- Tighten blocklists and custom regex.
- Check per-caller overrides.
- Validate L2 contract posture before traffic moves.
- Confirm sensitive embeddings are blocked or pinned local.
The dry-run loop matters because LLM traffic gets strange quickly. Tool outputs, scanned documents, CSV fragments, stack traces, source files, incident notes, and memory snippets do not look like clean chat messages.
The classifier has to see the mess before production does.
Audit Without Creating A New Leak
Audit is where security tooling can accidentally betray itself.
If a proxy logs the raw prompt to prove it made the right decision, the audit trail becomes a second copy of the sensitive data. That is not governance. It is duplicated exposure with nicer labels.
RuneLM hashes prompt and response content with HMAC-SHA-256 and writes metadata around the decision:
- caller identity
- session identity
- classification level
- selected route
- redacted entity count
- latency
- error code when blocked
- audit row identifier
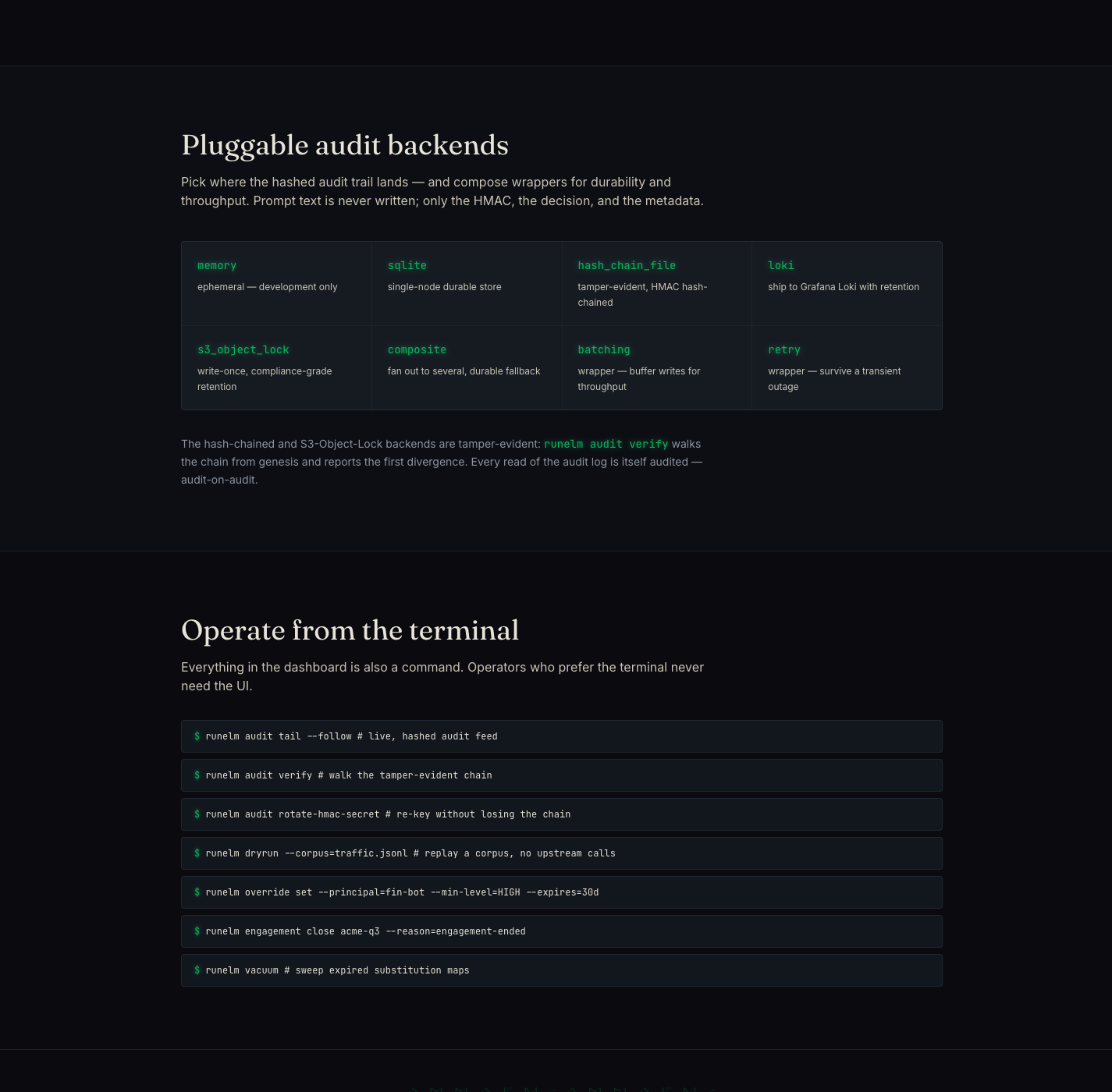
Durable audit backends include Loki, S3 Object Lock, and hash-chained files. Local storage is available for development, but the design is built for tamper-evident operation. Even reads of the audit log are audited.
That gives operators evidence without copying the payload they were trying to protect.
Why This Matters Now
The industry keeps treating model policy as a procurement artifact.
Contracts matter. Provider docs matter. ZDR matters. HIPAA readiness matters. Data residency matters.
But agents do not execute contracts.
Routers do.
An agentic framework can run hundreds of calls through memory retrieval, tool output, summarization, file parsing, code execution, and model fallback. A single provider policy change can make yesterday's route unsuitable for tomorrow's payload.
RuneLM gives that route a control plane.
It does not ask a developer to track which model is safe for which data class by hand. It encodes the boundary at the only place that sees every outbound call.
That is the standalone DSP thesis:
classify before capability,
pseudonymize before provider,
route before spend,
rehydrate only what you created,
audit without copying the secret.
The companies that run agentic systems cheaply will use tiered models, local inference, compression, prompt caching, and budget-aware routers.
The companies that run them safely will put a data boundary in front of those choices.
RuneLM is that boundary.
Private Alpha
RuneLM is in private alpha until June 30, 2026.
We are keeping the cohort small while operators test the proxy against real retention constraints, routing policies, prompt-caching paths, compression flows, and agentic workloads.
Join the waiting list here: https://blackunicorn.tech/waitlist
Sources checked: Anthropic API and data retention, Anthropic commercial training policy, Claude Code data usage, and The Verge reporting on Microsoft and Claude Fable 5.