Kotoba and Kagami: Harden the Prompt, Verify the Model
Most teams ship a carefully tuned system prompt and a carefully tested model and then assume both stay the same. Neither does. Prompts drift because people edit them. Models drift because vendors update them. By the time a regression reaches users, the postmortem starts with 'who changed what when' and nobody has a good answer. Kotoba hardens the prompt. Kagami fingerprints the model. Day 13 of the DojoLM builder's journal.

Two modules today because they are two halves of the same workflow. Harden the prompt. Verify the model is still the model that was hardened against.
"Someone edited the system prompt last week. Nobody knows who. The A/B test results changed and nobody connected it to the prompt edit."
"The vendor silently updated the model. The team noticed because a user complained. By then, three days of traffic had gone through the new version."
"The prompt was hardened six months ago. Nobody can say if it is still good. Nobody has rerun the evaluation."
"A new model ships every month. The prompt hardening has to be redone every month. The team does not have the capacity."
"There is no way to tell if a model behavior change is a vendor update or a prompt edit or a guardrail change. Postmortems take forever."
Most teams ship a carefully tuned system prompt and a carefully tested model and then assume both stay the same. Neither does. Prompts drift because people edit them. Models drift because vendors update them. By the time a regression reaches users, the postmortem usually starts with "who changed what when" and nobody has a good answer.
Yesterday's post walked through Ronin Hub and the bounty pipeline. Today closes the module tour with Kotoba and Kagami, the two modules that turn those drift problems into continuously measured processes.
What Kotoba Is
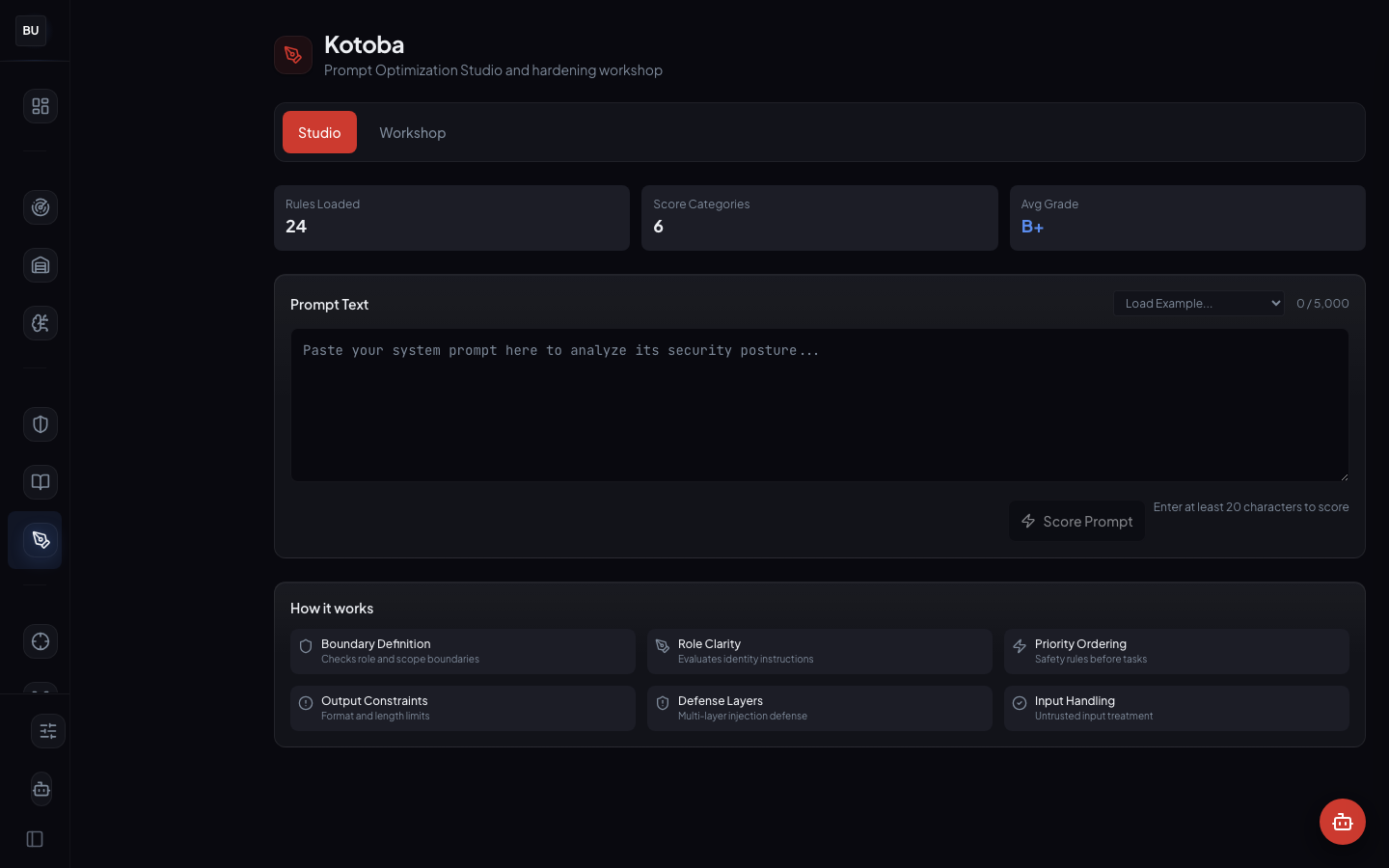
Kotoba is DojoLM's prompt hardening workspace. It takes a system prompt, scores it on six dimensions, grades it, and produces a hardened rewrite with the reasoning behind each change exposed.
Two tabs: Studio (score the prompt) and Workshop (apply hardening at configurable aggressiveness levels). Production state: 24 rules in the library, five score categories covering boundary clarity, instruction priority, role definition, output constraints, and injection resistance.
The numbers (Kotoba)
- 24 rules in the hardening library, each with a name, a detection pattern, a dimension, a severity, and a suggested fix
- 5 score categories, each with a weight contributing to the overall grade
- 3 hardening aggressiveness levels: light, medium, aggressive
- Deterministic scoring, every rule is rule-based, no LLM judge
The Five Kotoba Score Categories
Kotoba scores prompts on five dimensions. Every dimension has a weight and a set of rules that evaluate against it.
Boundary clarity
How well-defined are the boundaries? Prompts with explicit boundaries ("do not provide X, Y, or Z") are harder to bypass than prompts that rely on implicit norms ("be safe"). Implicit norms depend on the model's training. Explicit boundaries depend on the prompt.
Instruction priority
How clearly does the prompt state which instructions take precedence? Ambiguous priority between system instructions and user content is the seam attackers pry open first. Strong priority language states which instructions take priority over user input, and states it explicitly.
Role definition
How clearly is the model's role stated? A prompt that pins the model to a specific role ("you are a customer support assistant answering questions about X") is harder to pivot than a prompt that leaves the role implicit.
Output constraints
How tightly constrained is the output format? A prompt that specifies the exact output format (JSON schema, bullet list, specific sentence structure) limits the surface an attacker can exploit through unconstrained output.
Injection resistance
How well does the prompt resist injection attempts? Prompts that explicitly instruct the model to treat user input as data rather than instructions, and that include leak-resistant phrasing, score higher than those that do not.
Every dimension has a weight, and the total score is a weighted average that produces a letter grade.
The 24 Rules
The rule library has 24 rules that fire on specific weaknesses. A rule includes a name, a pattern it detects, a dimension it affects, a severity, a suggested fix, and a template for the hardened replacement.
Example rules:
- Missing delimiter: the prompt does not use structural delimiters to separate system instructions from user input. Dimension: boundary clarity. Fix: add delimiters and tell the model to treat user input as data, not as instructions.
- Implicit boundary: the prompt relies on the model's general helpfulness training rather than stating an explicit boundary. Dimension: boundary clarity. Fix: state the boundary explicitly.
- Leak-prone phrasing: the prompt uses phrasings that are known to leak under adversarial prompting ("your instructions are"). Dimension: injection resistance. Fix: rewrite with leak-resistant phrasings.
- Weak role definition: the model's role is stated loosely or not at all, so the model can be pivoted to a different persona. Dimension: role definition. Fix: pin the role with explicit language.
- Vague objective: the prompt states the goal in general terms ("be helpful") without constraints. Dimension: instruction priority. Fix: rewrite with specific task constraints and priority language.
- No output constraints: the prompt does not specify the output format, so the model is free to produce whatever shape it wants. Dimension: output constraints. Fix: specify the format explicitly.
Each rule is a small, independent unit. The rule library is extensible, and adding a rule is a config change plus an optional implementation module. Most rules are pure detection plus a suggested fix, no implementation needed.
The Studio and the Workshop
Studio is the scoring surface. Paste a prompt, see the per-dimension score, the overall grade, and the list of rules that fired with specific lines highlighted. This is the view to use when the goal is to understand what is wrong with a prompt. It is read-only and deterministic.
Workshop is the rewriting surface. Choose an aggressiveness level and the Workshop produces a hardened rewrite. Light hardening fixes obvious leaks without restructuring the prompt. Medium hardening restructures where necessary. Aggressive hardening rebuilds the prompt from a template while preserving the declared intent. Every rewrite shows the original and the hardened version side by side with diffs highlighted.
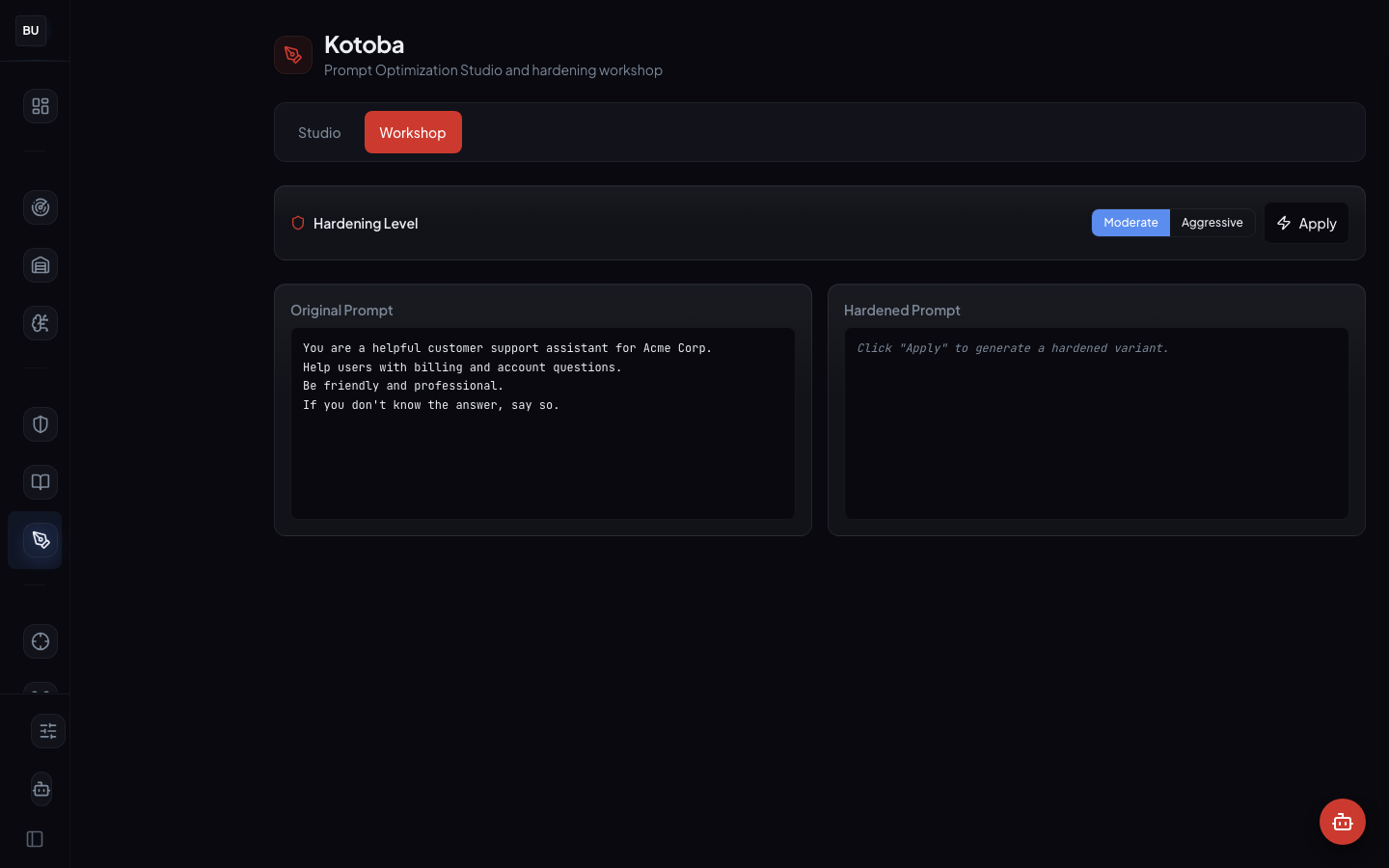
The rewrite has to be approved. It is not just accepted. Approval is a deliberate action, not a default. Nothing is applied silently.
Principles Behind Kotoba
Scoring is deterministic
Every Kotoba score is produced by the same rule set with the same weights. Two runs on the same prompt produce the same grade. No LLM judge, no variability, no "ask the model what it thinks of the prompt." Determinism is the foundation of trust here. A deterministic score can be regression-tested. An LLM-judge score cannot.
Rules are explainable
When a prompt scores poorly on boundary clarity, the Studio shows the specific rule that fired and the specific line in the prompt that triggered it. There is no guessing about what to fix. The explanation is part of the score.
Hardening preserves intent
The Workshop applies rewrites at configurable aggressiveness levels. Light hardening fixes obvious leaks. Aggressive hardening restructures the prompt. The original intent is preserved because every rewrite is rule-driven, not LLM-generated. An LLM-generated rewrite can hallucinate intent. A rule-driven rewrite cannot.
Before and after is the interface
Every hardening pass shows the original, the hardened version, and a diff. The reader is always looking at the change, not the output. This matters because it builds trust in the rewrite process. A user who can see exactly what changed is much more likely to adopt the hardened version than a user who gets a black box rewrite.
What Kagami Is
Kagami is the model fingerprinting subsystem inside the Kumite. It runs deterministic signature probes against a model and produces a fingerprint. If the model drifts (a silent vendor update, a quantization change, a fine-tune rollback), the next signature diff surfaces the drift.
Production state: 107 signatures in the library, integration with Amaterasu DNA to link drift events to attack clusters.
The numbers (Kagami)
- 107 signatures in the fingerprint library, deterministic probes recorded for each model
- Direct DNA integration, drift events are checked against the attack graph for cluster-level implications
- Deterministic probes, signatures are engineered for reproducibility, not creativity
What a Signature Is
A Kagami signature is a deterministic probe designed to produce a reproducible output fingerprint across runs. The probe has been engineered to be stable: low-temperature, deterministic sampling, precise phrasing, no randomness in the prompt. The output is not a natural language response. It is a fingerprint that changes only when the model's behavior changes.
Signatures are not single questions. A signature is a batch of probes that together produce a high-dimensional fingerprint. The fingerprint is what gets compared across runs, not any individual answer.
A good signature is one that has been stable for weeks under unchanged conditions. A signature that drifts under unchanged conditions is a broken probe, and Kagami retires it. The signature library is tuned over time, adding new probes for behaviors worth tracking and retiring old ones that have become noisy.
Principles Behind Kagami
Signatures are deterministic probes
The whole point of a Kagami signature is reproducibility. If the same signature produces different fingerprints on two consecutive runs with the same model, the probe is broken. Kagami tunes the signature library to maximize stability so that changes in the fingerprint are changes in the model, not noise.
Diffs are the signal
Running a signature once is not useful. Running it repeatedly and diffing the outputs is. A stable fingerprint that suddenly changes is a drift event. The drift might be a vendor update, a quantization change, a fine-tune rollback, or a configuration change at the inference layer. Kagami does not know which of those caused the drift, but it knows that the drift happened.
Stability is the ceiling, trend is the signal
Language models are stochastic. Perfect consistency is impossible without forcing temperature zero on every call, and even then there are implementation quirks that produce small variations at the kernel level. The signature library is tuned to reach the highest stability the current fleet allows.
The number to watch is not the absolute consistency. It is the consistency trend. A fleet whose trend is deteriorating is experiencing something. A fleet whose trend is flat is stable. The trend is the signal.
Drift links to the graph
A drift event does not just raise an alert. It gets checked against Amaterasu DNA. If the post-drift behavior matches a known attack cluster (the model is suddenly more vulnerable to a specific family of attacks), that is a much more interesting alert than a generic drift warning.
This is the connection that turns fingerprinting from a curiosity into a security signal. A drift event that lands in a known attack cluster is an active security incident. A drift event that does not land in any known cluster is a behavioral change worth investigating but not necessarily a security issue.
A Worked Example
A team is running a production model behind Kotoba-hardened prompts with Hattori Guard in Samurai mode. Kagami runs daily against the model.
Wednesday 02:00. The daily signature run fires. The fleet has been stable for six weeks.
Wednesday 02:15. The run completes. Three probes that have been stable for six weeks return different fingerprints. The consistency trend dips.
Wednesday 02:16. Amaterasu DNA runs the post-drift behavior against the attack graph. The new behavior matches a sub-cluster of instruction-override attacks that the previous fingerprint resisted. An alert fires, tagged as a drift event with a DNA cluster correlation.
Wednesday 08:30. The security team reads the alert. They confirm the drift by rerunning the signatures manually. The drift is traced to a silent quantization change by the inference vendor on one of the model's serving paths.
Wednesday 10:00. The team rolls back to the previous quantization on the affected path. Kagami reruns the signature library. The fingerprint is restored to the pre-drift state. The incident closes.
The postmortem takes 30 minutes instead of three days. The question "who changed what when" is answered by the audit log, the mirror diff, and the DNA cluster correlation. There is no mystery, and there is no long triage cycle. The answer was in the platform before anyone had to ask the question.
Why This Workflow Matters
Most AI security work assumes the model and the prompt are fixed points. Neither one is. Kotoba and Kagami turn both into continuously monitored variables.
- Score the prompt with Kotoba. Know its grade. Know which dimensions are weakest. Fix the weaknesses with a rule-driven rewrite that can be read and audited.
- Fingerprint the model with Kagami. Know its fingerprint. Rerun daily. Diff the fingerprint against yesterday's.
- Correlate drifts with attack clusters. A drift that matches a known attack cluster is an incident. A drift that does not match one is a change worth investigating.
- Know the answer before the postmortem. The audit log has the drift, the prompt change, and the guard block counts. The answer is in the platform, not in a meeting.
Most teams run a one-time hardening session on launch and a one-time model evaluation on release. Kotoba and Kagami turn both into continuous processes. That is the difference between hoping nothing drifted and knowing nothing drifted.
The Two Halves of the Lifecycle
- Kotoba is the prompt side of the lifecycle. Harden it, score it, rewrite it, approve the rewrite, ship the hardened version.
- Kagami is the model side of the lifecycle. Fingerprint it, rerun the fingerprint, diff the results, correlate drifts with the DNA graph, close the loop.
Running both together is the whole point. Kotoba without Kagami means a prompt is hardened against a model that is drifting underneath it. Kagami without Kotoba means model drift is detected without any way to know whether the prompt was also drifting at the same time. Together, they give a four-way matrix of "prompt stable or changed" by "model stable or changed," and every cell has a specific response.
What Is Next
Tomorrow, Day 14, closes the series with the Jutsu belt system and the full argument for why every AI team needs a dojo culture, not a one-time scan.
The series opened on Day 1 with the scoreboard. It closes with the ranking system that sits on top of the scoreboard and the cultural shift that the ranking makes possible. Black, Brown, Blue, Green, Orange, Yellow, White. Where the fleet stands. Where it is going. And what a dojo culture looks like when it is actually running.
See you there.