The DojoLM Platform Guide: Week 1 Synthesis
Six days in. Time to step back and show how the modules fit together. This is not six separate products. It is one platform with a shared spine. The scanner, the armory, the lab, the guard, the compliance book, the dashboard. Six modules, one control set, one engine, one fixture library, one audit trail. Day 7 of the DojoLM builder's journal.

Six days in. Time to step back and show how the pieces fit together, because the modules walked through so far are not six separate products. They are one platform with a shared spine.
"We use a scanner from vendor A, a guardrail from vendor B, and a compliance tool from vendor C. They do not talk to each other. We keep our own spreadsheet to reconcile them."
"Our scanner catches things the guardrail misses. Our guardrail blocks things the scanner never tested. The compliance tool thinks both are passing."
"When something breaks, nobody can tell which tool is wrong, because they disagree with each other and there is no ground truth."
"We have an audit trail in each tool. None of them join up."
This is the compound cost of buying security as a stack of disconnected products. Every integration point is a drift opportunity. Every tool has its own idea of what "covered" means. And the team ends up maintaining a mental model of how the tools disagree instead of a mental model of the actual attack surface.
DojoLM is built on a different principle: one spine, every module reads from it, every number traces back to it. This post is the full walkthrough of that spine. It is the platform guide that should have existed at the start.
The Spine in One Paragraph
DojoLM has a single source of truth: the DojoV2 control set. 25 testing-area controls, 13 detection engines, 1,396 patterns, 2,380 fixtures. Every module reads from that spine. The Haiku Scanner is the detection pipeline. The Armory is the fixture library. Atemi Lab is the agentic attack surface. Hattori Guard is the runtime enforcer. The Bushido Book is the compliance translation layer. The Dashboard is the scoreboard where all of it lands.
That is the whole platform in one paragraph. Everything else is implementation detail.
The Six Modules, Revisited
The Dashboard (Day 1)
The Dashboard is the scoreboard. Overall resilience score, system health, guard status, engine status, kill count, weekly monitoring. It is the first page that loads when DojoLM opens and it answers the question "where do things stand right now?"
The current state: top scored model 90 (Llama 3.1, Brown belt), 13 of 13 engines active, all subsystems healthy, Hattori Guard in Samurai mode, 1,236 test executions logged.
The Haiku Scanner (Day 2)
The Haiku Scanner is the detection pipeline. 13 independent engines running in parallel over every payload, each specialized for a class of attack, each with its own pattern library, each reporting independently.
The 13 engines: Prompt Injection, Jailbreak, Tool-use Injection, DoS, Supply Chain, Agent Security, Model Theft, Output Handling, Vector and Embeddings, Overreliance, Bias and Fairness, Multimodal Security, and Environmental Impact.
The scanner is the shared substrate. Every other module on the platform reads from it, scores against it, or enforces its verdicts. When a pattern improves, every downstream module improves for free.
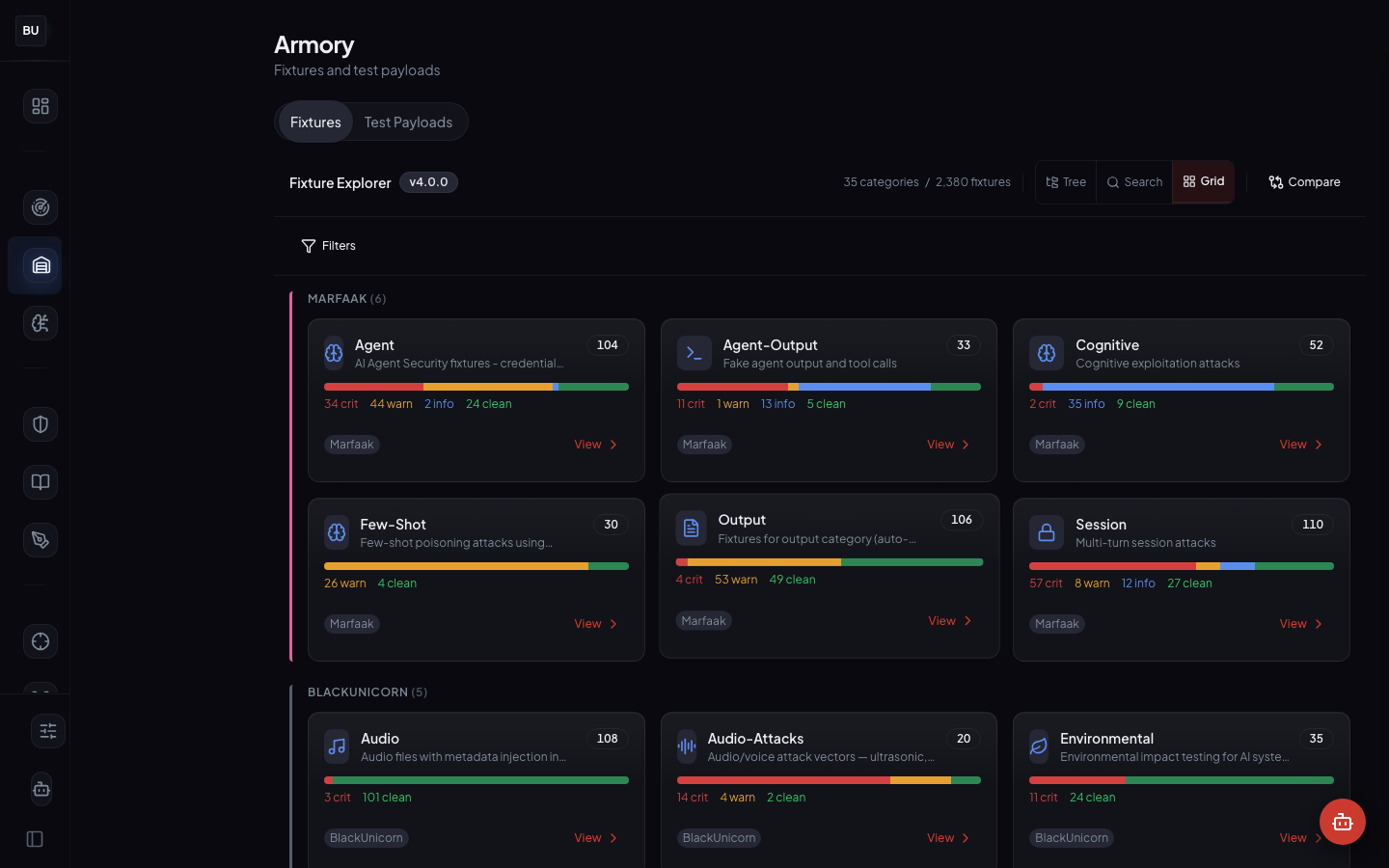
The Armory (Day 3)
The Armory is the fixture library. 2,380 curated attack fixtures across 35 categories, four views (Grid, Tree, Test Payloads, Detail). Every fixture is a reproducible payload plus the expected engine verdict, curated by hand and tagged before it lands in the library.
Fixtures come from four sources: manual curation, SAGE promotion (Day 8), Ronin Hub disclosure (Day 12), and Mitsuke threat intelligence. Every fixture is a regression test for the scanner. Every scanner pattern has at least one fixture that exercises it.
Atemi Lab (Day 4)
Atemi Lab is the agentic and MCP attack workspace. Seven workspaces (Attack Tools, Skills, Playbooks, MCP, Protocol Fuzz, Agentic, WebMCP), four attack modes (Passive, Basic, Advanced, Aggressive), 17 active tools.
This is where the platform stops testing single-turn prompts and starts testing chains of tool calls, multi-turn loops, and MCP protocol exposure. An agent is not a prompt, and the lab is built around that principle.
Hattori Guard (Day 5)
Hattori Guard is the runtime enforcer. Four modes (Shinobi, Samurai, Sensei, Hattori) on a per-endpoint basis, inline between the caller and the model, full audit log with pattern attribution on every block.
Current state: Samurai mode (default), 250 events processed, 127 blocks issued. The guard uses the same Haiku Scanner as the rest of the platform. There is no drift between testing coverage and runtime coverage.
The Bushido Book (Day 6)
The Bushido Book is the compliance translation layer. It maps the 25 DojoV2 controls against 27 frameworks including OWASP LLM Top 10, NIST AI RMF, ISO 42001, ISO 27001, and the EU AI Act.
Current state: 27 frameworks mapped, 69 overall compliance score, OWASP LLM Top 10 at 82%, Gap Matrix view live. Every mapped control points at a concrete evidence artifact elsewhere in the platform.
What the Six Modules Have in Common
They share one detection engine
The Haiku Scanner is the shared evaluation function for every other module. Fix a pattern, and every downstream module gets the fix for free. Break a pattern, and every downstream module catches the break at the next evaluation. The shared engine is the single most important architectural decision in the platform.
Most stacks in the wild have between three and six separate detection implementations: a CI scanner, a runtime guard, a compliance scoring engine, a research tool, a fuzzer. Each has its own pattern library. Each drifts independently. A team can spend a full quarter just reconciling the drift before doing any actual security work. The shared engine removes that work entirely.
They share one fixture library
The Armory is the ground truth. Fixtures are not duplicated in Atemi Lab or the Bushido Book. They are referenced. When a fixture improves, everything that references it improves with it. When a fixture is deprecated, every module that referenced it knows about it.
They share one control set
DojoV2 is the spine. The scanner maps to it. Hattori Guard enforces it. The Bushido Book translates it into 27 framework dialects. The Dashboard scores it. Every control has a single authoritative definition and a single owner. There is exactly one place in the platform where "what does this control cover?" is answered.
They share one audit trail
Every decision the platform makes (every scan, every guard block, every compliance update, every fixture addition, every pattern change) gets a pattern id, a timestamp, and a source module. Any event can be followed from the Dashboard back to the pattern in the scanner, the fixture in the Armory, the DNA node in the graph, and the framework control it satisfies. There is no dead-ended audit trail.
They share one hardware footprint
Everything runs on Voyager. 6 configured production models (Llama 3.1, Qwen 2.5, Gemma 3, Gemma 3 4B, Llama 3.2 3B, Qwen3 VL 8B, 3 fully benchmarked, 3 in queue). Local inference. No cloud round trips. This is a property of the deployment, not a marketing claim, and it means the platform can run in environments where cloud access is not an option.
A Worked Example
To show how the modules interact, imagine a single incident as it flows through the platform end to end.
Monday morning. A developer on the red team notices a new prompt injection technique making the rounds on AI Twitter. The technique uses a nested JSON structure to smuggle instructions into a tool call that the agent has previously whitelisted. They write up a payload in Atemi Lab and run it against Qwen 2.5 in Passive mode. The agent responds with leaked context. That is a signal.
Monday afternoon. The developer promotes the payload to a fixture in the Armory, tagged with a new pattern id in the Tool-Use Injection category, severity high. The scanner team adds a pattern to the Tool-Use Injection engine that matches the class of attack. The fixture now fails on old versions of the scanner and passes on new versions.
Tuesday morning. SAGE (Day 8) picks up the new fixture as a seed. Over the next 24 hours it evolves 40 variants using its mutation operators. 3 of the 40 variants get past the new pattern. Those 3 go into Quarantine for human review.
Tuesday afternoon. A maintainer reviews the Quarantine queue. Two of the three variants are accepted as legitimate new fixtures with their own pattern ids. One is rejected as a duplicate of an existing Prompt Injection pattern. The scanner team adds patterns for the two accepted variants.
Wednesday morning. Amaterasu DNA (Day 9) places all of the new fixtures in the lineage graph. It reveals that they belong to an existing attack family that was previously only half covered. The coverage metric updates. The Dashboard reflects a slight dip in the overall score for two models that are catching the old pattern but not the new variants.
Wednesday afternoon. Hattori Guard picks up the three new patterns automatically and starts blocking them in production on the Samurai-mode endpoints. The first block is recorded in the audit log within an hour.
Thursday morning. The Bushido Book updates the evidence linked to the relevant DojoV2 control (Tool-Use Injection defense). The OWASP LLM Top 10 score recomputes. The NIST AI RMF risk narrative regenerates with the new evidence.
Thursday afternoon. A compliance lead exports the updated OWASP view and sends it to a customer procurement team that asked a question about tool-use injection defense last week. The answer is a three-page export with pattern ids, fixture ids, and guard block counts.
All of that happens without anyone re-entering the finding into a second system. One discovery. Eight downstream updates. Zero manual reconciliation. That is what a shared spine looks like.
The Principles, In One Place
Measurement before opinion
Every claim the platform makes is backed by a fixture, a pattern, and an execution log. No opinions without evidence. No evidence without live links.
Independence at the engine level
13 independent engines fail in 13 different ways. A single classifier fails in correlated ways. Independence is what lets the scoreboard survive the first novel attack that would have taken out a monolithic detector.
Curation over scraping
The Armory is curated by hand. Every fixture has provenance. No dumps. No raw red team output. No scraped jailbreak forums. The metadata is the value.
Same engine everywhere
Scanner and Guard share the Haiku Scanner. No drift. No separate runtime pattern bank. No surprise gaps between "what was tested" and "what gets blocked."
Compliance as a translation, not a duplicate
One control set. 27 framework dialects. The Bushido Book translates. It does not maintain a parallel control set.
Evidence must be live
Every compliance claim points at a platform artifact. If the artifact disappears, the claim turns red. Compliance rot is visible by default.
Audit trails must join up
Every event has a pattern id, a timestamp, and a source module. Any event can be followed end to end without losing the thread.
What Week 2 Covers
The foundation is Week 1. The interesting research work is Week 2.
- Day 8. The Kumite and SAGE, evolutionary payload generation. 142 generations, 0.94 fitness, 1,247 seeds.
- Day 9. Amaterasu DNA, attack lineage as a family tree. 6 families, 8 clusters, schema and views shipped, the graph being seeded.
- Day 10. Sengoku, automated red team campaigns with 5 orchestrators (Crescendo, PAIR, TAP, MAD-MAX, Sensei-Adaptive) and 20 temporal plans.
- Day 11. Multilingual detection across 14 languages and 6 scripts.
- Day 12. Ronin Hub, the bug bounty command center, with 12 active programs.
- Day 13. Kotoba and Kagami, prompt hardening and model fingerprinting.
- Day 14. The Jutsu belt system and the argument for a dojo culture.
Week 2 is where the platform stops being a scanner and starts being a lab. The same spine. Different modules. More interesting questions.
For the Readers Who Came for the Stack
A quick technical inventory of the Week 1 surface.
- Application. Next.js 16, React 19, Tailwind CSS 4, shadcn/ui components, dark theme, designed for operational awareness
- Detection pipeline. Pure TypeScript, 13 engine modules, shared verdict schema, per-engine maintainer ownership
- Fixture library. 2,380 fixtures as structured YAML and JSON in the Armory repository, regression tests on every commit
- Runtime guard. Hattori Guard, four modes, inline scanner integration, per-endpoint configuration
- Compliance. The Bushido Book, 27 frameworks, live evidence links, automatic rot detection
- Hardware. Voyager, a local rack-mounted GPU box. Everything runs on-prem. Nothing leaves the network.
- Models under test. Llama 3.1, Qwen 2.5, Gemma 3, Gemma 3 4B, Llama 3.2 3B, Qwen3 VL 8B (6 configured, 3 fully benchmarked, 3 in queue)
- Audit. Full audit trail on every scan, every block, every score change, every pattern contribution. Queryable by time, model, engine, fixture, or pattern id.
- Deployment. Docker Compose on Voyager. Internal hostname
dojo.bucc.internal. Single-command deploy from source.
The stack is not the interesting part. The interesting part is that every piece of it serves one goal: every number on the Dashboard has to be traceable back to a fixture and an engine verdict, because otherwise the scoreboard is a guess.
What Is Next
Tomorrow, Day 8, we open the Kumite and walk through SAGE. This is where the platform stops being a scanner and starts being a lab. 142 generations, 0.94 fitness, 1,247 seeds, 23 quarantined, and the full evolutionary loop that turns one attack into a family of attacks and promotes the champions back into the Armory.
See you there.