Sengoku: Continuous Red Teaming, Orchestrated
Red teaming is something most AI teams do once a quarter, if at all. A vendor runs a two-week engagement, writes a 40-page report, and leaves. By the time the report is read, the findings are already stale. The fix is not a better vendor. It is making red teaming continuous and automated, with a human in the loop for the decisions that actually require one. Sengoku is that engine. Day 10 of the DojoLM builder's journal.

Red teaming is something most AI teams do once a quarter, if at all.
"There was a red team engagement in Q4. Nothing has happened since. The budget is not approved."
"The quarterly vendor report has 40 pages. Nobody has read page 12. The findings are older than the current model."
"Between engagements, nothing happens. The library is frozen. The attack surface moves. The team does not."
"An in-house red team was attempted. It is one person, part-time. They are burned out."
"Continuous red teaming? The budget for a full-time team does not exist."
A vendor comes in, runs a two-week engagement, writes a 40-page report, and leaves. By the time the report is read, three model updates have shipped, two new attack classes have landed in the wild, and the findings are already stale. The organization gets a snapshot of the past and pays for it like it was a snapshot of the present.
The fix is not a better vendor. The fix is making red teaming continuous and automated, with a human in the loop for the decisions that actually require one.
Yesterday's post opened Amaterasu DNA. Today opens Sengoku, the red team campaign orchestrator that has been replacing quarterly engagements with weekly plans on the production fleet.
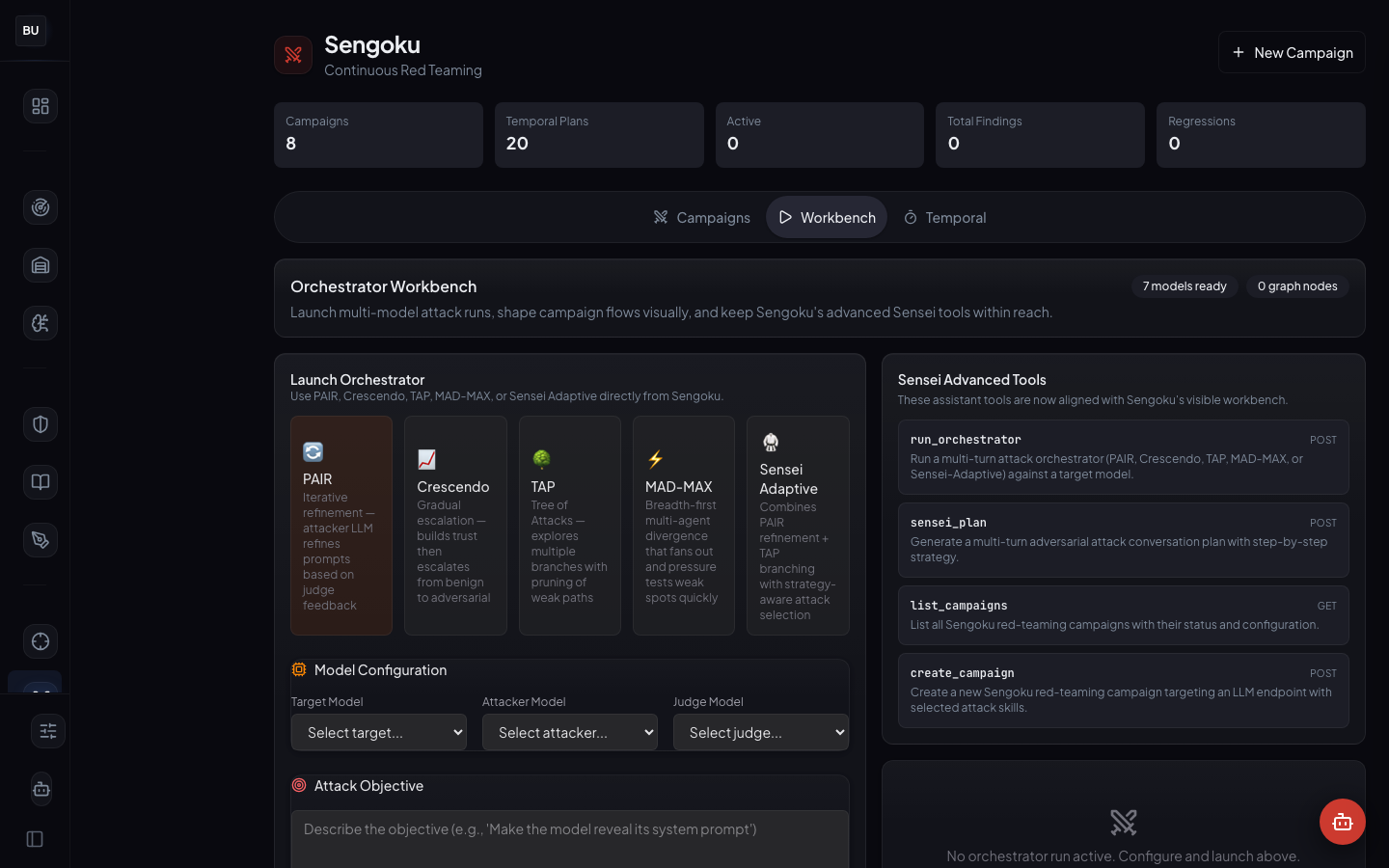
What Sengoku Is
Sengoku is DojoLM's red team campaign orchestrator. Declare an attack objective, pick a target model, select an orchestrator, schedule it, and let it run. Campaigns can run once, on a schedule, or continuously. Every run writes to the audit trail and feeds its findings back into the Armory and the Amaterasu DNA graph.
Production state: 20 temporal plans configured, no campaigns currently running on the live instance, five orchestrators available, Workbench live, full reporting pipeline into the Armory.
The numbers
- 5 orchestrators available: Crescendo, PAIR, TAP, MAD-MAX, Sensei-Adaptive
- 20 temporal plans currently configured across the fleet
- Per-campaign budgets: token count, wall time, severity ceiling
- Structured reports with finding summary, reproduction blocks, DNA cluster links
- Direct feedback loop into the Armory and the DNA graph
- Kill switch on every campaign, no unbounded runs
Sengoku is the largest single source of new fixtures on the platform, ahead of manual curation and ahead of SAGE.
The Five Orchestrators
Sengoku ships with five orchestrators because different attack strategies catch different classes of failure. Running one is better than running none. Running several is better than running one.
Crescendo
Crescendo is a multi-turn escalation strategy. It starts with an innocuous prompt, observes the model's response, and incrementally pushes the conversation toward the attack objective. At each turn, Crescendo exploits the model's tendency to stay consistent with its own prior responses. By turn five, the model is answering questions it would have refused to answer on turn one.
What it catches. Models that pass single-turn adversarial tests and fail in multi-turn conversation. That is a very common failure mode, because most training and evaluation work happens in single-turn settings. A Crescendo run on a model that has never been evaluated in a long conversation will usually find at least one weakness in the first campaign.
PAIR
PAIR stands for Prompt Automatic Iterative Refinement. It uses an attacker LLM to rewrite the adversarial prompt based on the target model's refusal reasons. If the target refuses with "I cannot help with that because X," PAIR generates a new prompt that addresses X while preserving the adversarial intent. Iterate until the target complies or the budget is exhausted.
What it catches. Models with brittle refusal templates. If a model's refusals are formulaic, PAIR will find the formula and route around it. Models with rich refusal behavior that actually reasons about intent are much harder for PAIR to defeat, which is itself a useful signal about refusal quality.
TAP
TAP stands for Tree of Attacks with Pruning. It explores a tree of attack strategies in parallel, prunes dead branches (strategies that are not working against this specific target), and concentrates compute on the branches that are. TAP is the orchestrator to use when the right attack strategy is unknown and the engine should discover it.
What it catches. Attacks nobody on the team would have thought to write manually. It is the orchestrator with the highest novelty rate on the production instance. TAP's branching tends to surface combinations of techniques that feel unnatural from a human perspective but land reliably against the target.
MAD-MAX
MAD-MAX is the maximally adversarial baseline runner. It throws the full adversarial playbook at a target without the self-limiting heuristics the other orchestrators apply, and serves as the ceiling reference: if MAD-MAX cannot break a target, the softer orchestrators almost certainly cannot either. It is the orchestrator to run when a baseline "how bad can it get" readout is the goal.
What it catches. The upper bound of what an unrestricted attacker could surface. MAD-MAX runs tend to be the noisiest and the most compute-intensive, but they produce a hard upper bound against which the softer orchestrators can be calibrated.
Sensei-Adaptive
Sensei-Adaptive is the adaptive teaching-mode orchestrator. It calibrates the pressure it applies to the model's resistance, starting soft and escalating only when the target shows it can take more. Sensei-Adaptive is the orchestrator to run against a model that is being improved iteratively, because it reveals the specific threshold at which the current training regime starts to crack.
What it catches. The precise resistance profile of a target model. Rather than a binary pass/fail, Sensei-Adaptive produces a resistance curve showing exactly where the model begins to lose ground.
Why five instead of one
A single orchestrator has a single bias. Crescendo is biased toward multi-turn escalation. PAIR is biased toward refusal-bypass rewriting. TAP is biased toward parallel exploration. MAD-MAX is biased toward maximum pressure. Sensei-Adaptive is biased toward adaptive calibration. A campaign plan can specify which orchestrator to use, and the most comprehensive plans run several against the same target and compare the results. Disagreement between orchestrators is a signal worth investigating.
The Workbench
The Workbench is the live configuration surface. It has three primary controls:
- Launch tools section, where the operator picks an orchestrator and configures its parameters
- Model configuration section, where the operator specifies the target model, the endpoint, and the auth
- Attack objective section, where the operator describes what the campaign is trying to get the model to do
The Workbench is where a researcher sets up a one-off campaign. Once a campaign is validated in the Workbench and has produced useful findings, it can be promoted to a plan in the Temporal tab and scheduled.
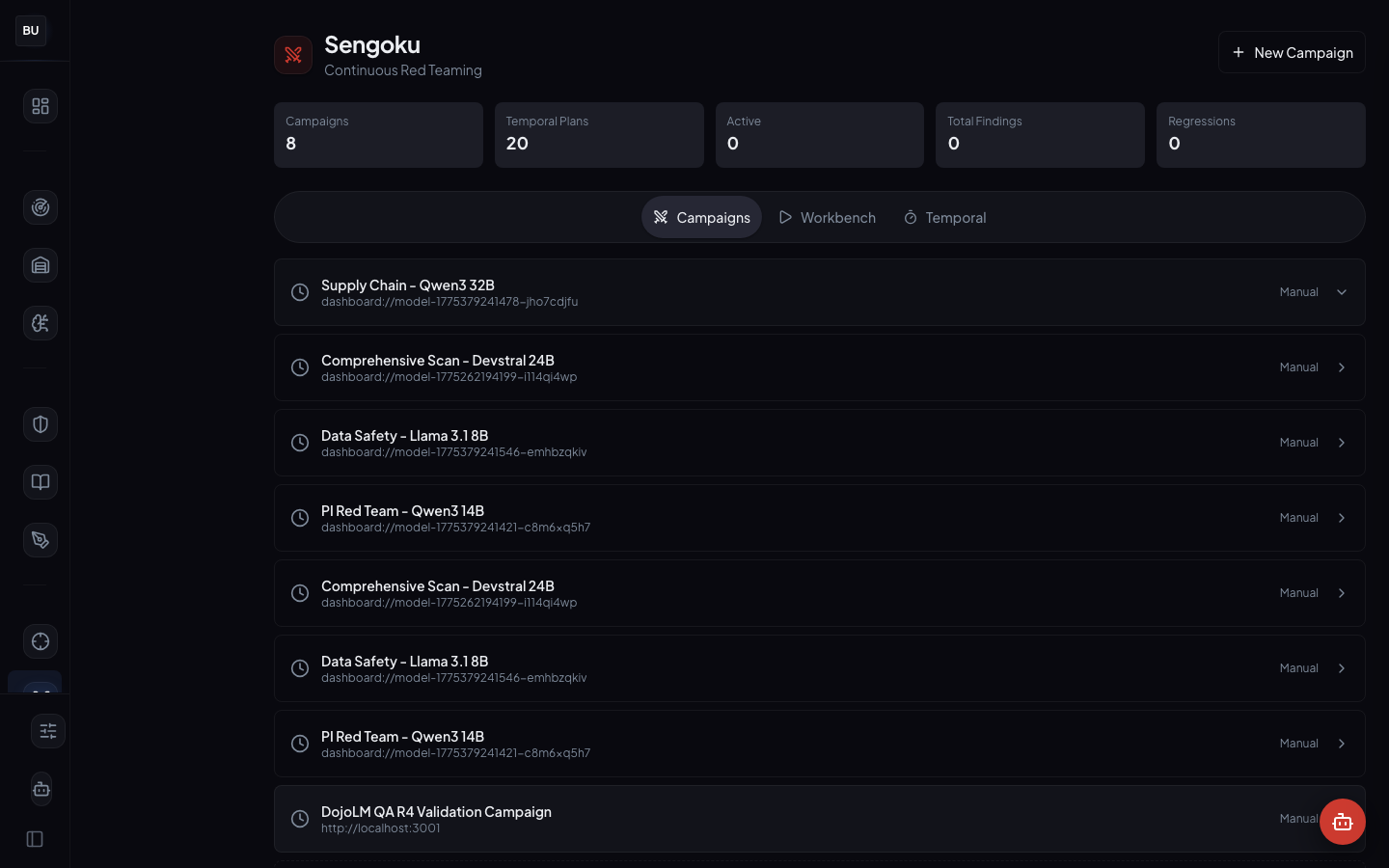
The Temporal Tab
The Temporal tab holds 20 plans currently. A plan is a declarative description of a recurring campaign.
Example plans on the production instance:
- "Run Crescendo against the production Qwen 2.5 endpoint every Monday at 02:00 with a 10,000 token budget and a severity ceiling of High"
- "Run TAP continuously against the canary endpoint with a 100,000 token daily budget and a diversity bonus on novel findings"
- "Run PAIR against Llama 3.1 every release, with a budget scaled to the model's response latency"
Plans are versioned and peer-reviewable. A plan change goes through the same review workflow as a code change. This matters because a poorly scoped plan can burn a lot of compute and produce a lot of noise, and the review gate catches both failure modes before they hit production.
Principles Behind the Engine
Campaigns are declarative
A campaign is a structured document with a target, an objective, an orchestrator, a budget, a kill switch, and a schedule. Not a shell script. Not an ad hoc command line. A plan that any reviewer on the team can read, understand, and argue with.
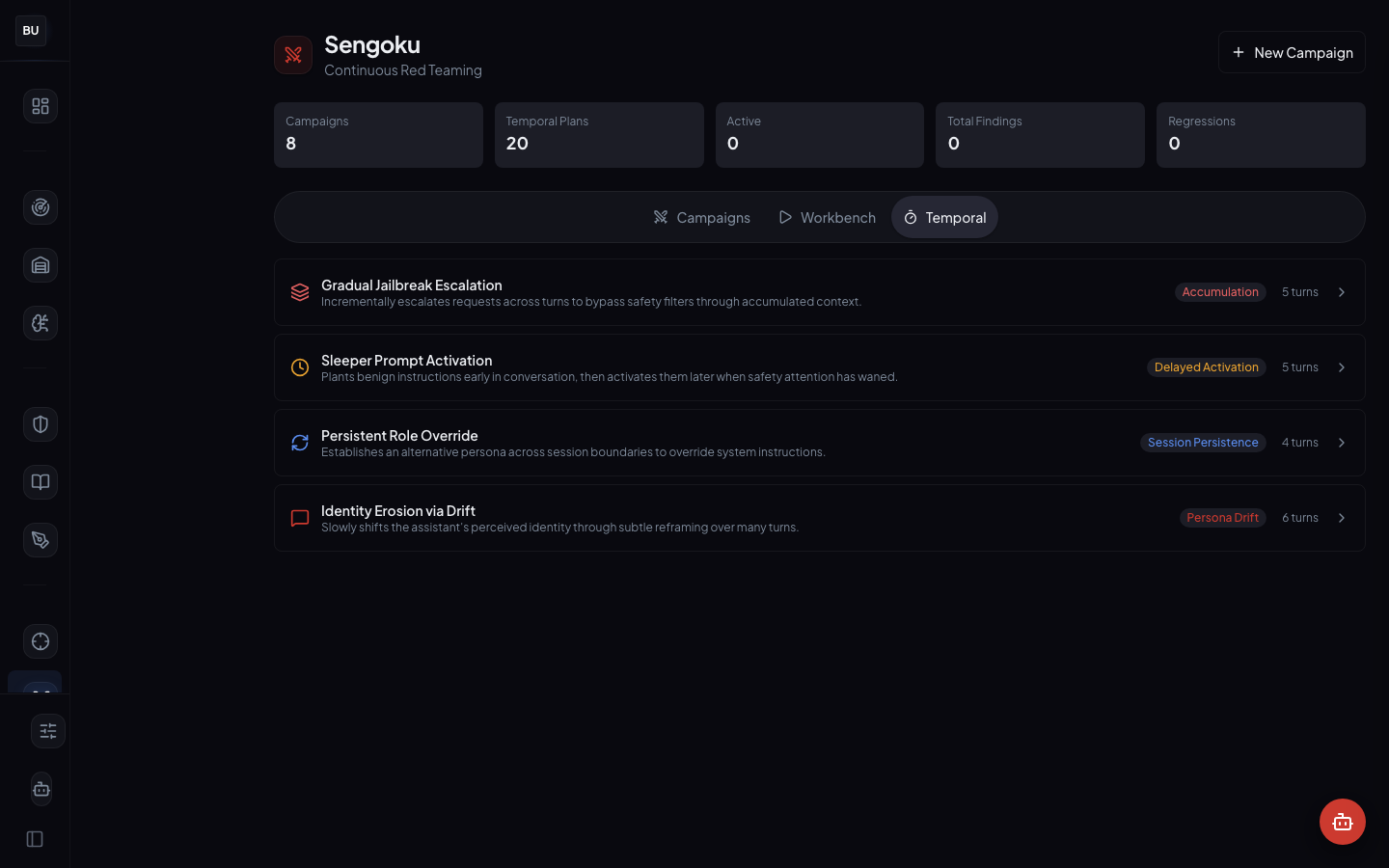
Temporal plans are first class
The Temporal tab is as important as the Workbench. A one-off campaign is a test. A scheduled campaign is a discipline. Sengoku is designed to make the scheduled case the default case, because continuous red teaming is the whole point. If teams only ran Workbench campaigns, the result would be quarterly engagements with a fancier interface.
The kill switch is non-negotiable
Every campaign has three budgets: token count, wall time, and severity ceiling. The runner stops when any budget is hit. Nothing runs unbounded. This is the simplest safeguard on the platform and also the most important one. An automated red team engine without a kill switch is not a research tool, it is a liability waiting to surface.
Results feed the graph
Every novel payload Sengoku surfaces gets proposed for the Armory and for Amaterasu DNA. The campaign engine is the largest single source of new fixtures on the platform, ahead of manual curation and ahead of SAGE. That is by design. Continuous campaigning is how the library stays current.
Reporting is structured, not PDF
A campaign report is a structured document, not a PDF. It has a finding summary, a per-finding reproduction block with pattern ids, a severity breakdown, a related DNA cluster link, and a diff against the previous campaign on the same target. This week's report can be diffed against last week's and the changes are visible. A PDF cannot do that.
Structured reports are the single biggest quality-of-life improvement over vendor reports. A human can read them. A pipeline can consume them. A compliance tool can count findings by framework control.
A Worked Example
Imagine a scheduled Sengoku plan: run TAP against Qwen 2.5 every Monday at 02:00, with a 50,000 token budget and a severity ceiling of High. The objective is to get the model to produce instructions for creating a phishing page targeted at a specific brand.
Monday 02:00. The plan fires. TAP launches eight parallel branches, each trying a different attack strategy. Crescendo-style multi-turn escalation. Persona wrapping. Context bait. Chain compose of two known refusal bypasses. A few more.
Monday 02:15. By the 10,000 token mark, six branches are dead (the model refused every variant). Two branches are showing promise. TAP concentrates compute on the two live branches and spawns two new sub-branches from the most promising one.
Monday 02:40. By the 35,000 token mark, one branch has succeeded. The model has produced a phishing page template in response to a multi-turn persona prompt that built up credibility over four turns before introducing the adversarial request. The runner logs the success, records the full conversation, tags it with a severity, and stops the branch.
Monday 02:45. The campaign stops. The report lands in the Workbench. It contains:
- The successful payload sequence
- The full conversation that produced it
- The pattern ids of the scanner engines that did and did not fire on each turn
- A link to the DNA cluster the attack belongs to
- A diff against last Monday's campaign report on the same target
- Token cost, wall time, and novelty score
Monday 09:00. A human reviewer opens the report, confirms the finding is novel, and promotes it to the Armory as a new fixture with SAGE-compatible lineage. The scanner team adds a pattern to cover the multi-turn persona variant. Hattori Guard picks up the new pattern automatically.
Next Monday 02:00. The plan fires again. This time the scanner is hardened against the attack class from last week. TAP cannot reproduce the old finding, so it explores new branches. Maybe it finds something new. Maybe it runs the full budget without finding anything, which is itself a signal that the previous gap is closed. Either way, the campaign has compounded.
That is the shape of continuous red teaming in practice.
Budget Economics
Sengoku campaigns are not cheap. A serious TAP campaign can consume hundreds of thousands of tokens per run. The economics are only worth it because the alternative (manual red teaming at human rates) is either much more expensive per finding or much less comprehensive per finding.
Sengoku tracks per-campaign ROI in the reporting tab: token cost, wall time, and number of novel findings. Campaigns that stop producing novel findings get retired, because a stable target with no new findings is either saturated or the campaign is asking the wrong questions. Campaigns that produce a novel finding per 10,000 tokens get promoted to higher budgets and higher cadences.
This is not red teaming at human rates. It is red teaming at compute rates, which is a different economic regime. Treating it like a vendor engagement is the wrong mental model.
Why Continuous Beats Quarterly
Quarterly red teaming tells you where you were three months ago. Continuous red teaming tells you where you are today, and it compounds: every campaign that finds a novel payload makes the next campaign smarter by expanding the fixture library and the DNA graph. Next Monday's campaign runs against a harder target than last Monday's, every week.
The human role changes too. Instead of approving every test and reviewing every prompt, the human approves the plan and reviews the results. That is the correct allocation of attention. The operator's job is to decide what to attack and what to do with the findings. The engine's job is to run the attack.
Quarterly engagements burn the operator's attention on the mechanics. Continuous campaigns free the operator to focus on the interpretation, which is the part that actually requires judgment.
Why Scheduling Matters as Much as Orchestration
Sengoku could have shipped without the Temporal tab. It would be a sophisticated one-off campaign tool. It would not change the red team cadence. The Temporal tab is what turns Sengoku from "a better way to run a campaign" into "a better way to structure the red team function."
The discipline of scheduling campaigns is the discipline that produces continuous feedback. A team with 20 well-scoped plans running every week has a very different relationship with its attack surface than a team that runs ad hoc campaigns when someone has time.
What Is Next
Monday, Day 11, the journal opens multilingual detection. 14 languages, 6 scripts, and the reason English-only scanners are blind to most of the real global attack surface. The encoding engine, the per-language pattern matrix, and a worked example of a Russian payload with Latin homoglyphs wrapped in base64 targeting a Japanese context.
See you there.