Running 25 AI Agents in Production: Introducing BUCC
Several months, 600+ endpoints, 145+ tables, and a production-grade operations platform for a 30+ agent AI workforce. A builder's journal on what multi-agent AI actually looks like when it's running, not demoing.

The hype cycle around agentic AI is deafening. Every week brings announcements of new agent frameworks, new reasoning models, new "autonomous" capabilities. But when you talk to teams actually deploying these systems in production, you hear a different story.
"We have two agents and they keep stepping on each other."
"We built governance checks, but they slow everything down."
"We have no idea what our agents did last Tuesday."
"We provisioned ten agents at once and none of them worked."
"An agent tried to execute something it wasn't supposed to, and we only found out in post-mortems."
The gap between the rhetoric and the reality is enormous. Most multi-agent deployments fail because infrastructure isn't mature. Teams are stitching together frameworks, APIs, and custom code without thinking about governance, audit, memory, capacity management, or human oversight.
That's expensive. That's dangerous. That's where BUCC came from.
The Command Centre for Your AI Workforce
We've spent the last months building a production-grade multi-agent operations platform designed to manage 30+ AI agents with governance, memory, security, and human oversight as first-class citizens.
BUCC isn't a framework wrapper. It's not a research project. It's a full-stack, self-hosted operations system that treats multi-agent management the way you'd treat managing a real organization: with structure, accountability, communication, learning, and fail-closed security.
The Numbers
- 600+ API endpoints handling everything from agent provisioning to memory retrieval to incident response
- 145+ relational database tables tracking agent state, work assignments, governance decisions, approvals, audit trails, memory, and financial tracking
- 3-layer LLM routing intelligently distributing inference across local models, subscription services, and pay-per-token providers
- 3-tier action classification (T1 auto-execute, T2 notify, T3 block-until-approved) ensuring human oversight is proportional to risk
- 5 circuit breakers providing graduated governance control from soft pauses to hard stops
- 30+ agent fleet operating across finance, cybersecurity, research, operations, communications, and planning domains
- Multi-scope persistent memory via mem0 (global, team, agent scopes) enabling learning and coordination over time
- Real-time CEO Dashboard with 9 widgets tracking fleet health, approvals, security, financials, and operations
- Integrated tool ecosystem including financial operations, communications, browser automation, meeting intelligence, and research platforms
- Full audit trail of every decision, every action, every approval, every error
This isn't theoretical. It's running in production right now.
Why Most Multi-Agent Systems Fail
Before we built BUCC, we tried the conventional approach. You build agents. You add guardrails. You deploy them. And then reality hits.
Problem 1: Governance Debt
Most teams think governance is a feature you add after the fact. Input filters. Output validation. API key restrictions. But governance isn't a layer on top of agents, it's an architecture question.
When you're running 25 autonomous systems, you need:
- Graduated risk levels for different types of actions
- Approval queues for consequential decisions
- Real-time visibility into what agents are actually doing
- Emergency stop capabilities
- Regular testing of your governance controls
- Detection of unauthorized AI usage
If you don't design for this from day one, you end up bolting it on with duct tape. Then you can't remove the duct tape without breaking things.
Problem 2: Memory Fragmentation
Agents operate in isolation. Every conversation is context-window scoped. Agents can't learn from past work. They can't coordinate effectively with each other. They're amnesiacs running in parallel.
Real organizations don't work this way. People remember what happened yesterday. They learn from mistakes. They coordinate on shared goals. Your agents should too.
But building memory at scale is hard. You need vector embeddings, semantic search, consistency guarantees, and smart lifecycle management (when do you keep memories? When do you archive them?).
Problem 3: Capacity Blindness
You provision 10 agents and assign them work without knowing if they can actually handle it. Maybe Agent A is swamped but you queue up 5 more tasks anyway. Maybe Agent B is idle. You have no visibility into capacity.
Real fleet management requires knowing: How many concurrent tasks can Agent X handle? How many open slots do we have right now? Which agent should take the next job?
Without this, you end up with queued work that sits forever and agents that crash under load.
Problem 4: Audit Black Holes
You need to answer questions like:
- What did Agent X do on March 15th?
- Who approved that financial transaction?
- Why didn't Agent Y complete the task?
- When did that policy violation occur?
- What was Agent Z's decision-making process?
Without comprehensive audit trails, you can't answer any of these. You're flying blind.
Problem 5: Tool Integration Hell
Your agents need to operate in the real world. They need to access financial systems, send communications, browse the web, understand meetings. Each integration is a security and reliability problem. You need to:
- Authenticate securely
- Log all usage
- Track credit/cost
- Control which agents can access which tools
- Detect abuse
Most teams solve this with custom scripts and hope.
Problem 6: Governance vs. Velocity
There's a false choice: governance or speed. Either you lock everything down (slow) or you let agents run free (risky).
Good governance design doesn't create this trade-off. The right approval system should actually speed things up by removing uncertainty. The right visibility should reduce incident response time. The right memory should let agents work more efficiently.
BUCC is built on the principle that governance and velocity aren't opposed, they're aligned.
The BUCC Solution: 4 Surfaces, 1 Operating System
We organized the platform around 4 main operational surfaces:
1. The CEO Dashboard
This is mission control. A single screen where the decision-maker can see:
- Fleet Status: Real-time view of all agents, their state, current workload, utilization, alert summary
- Approvals Queue: Pending decisions requiring human judgment, with SLA tracking and priority management
- Security Alerts: Policy violations, unauthorized access attempts, shadow AI detection results, governance control failures
- Financial Tracking: Tool credit usage, operational spend, budget utilization across all tool providers
- Workload Summary: Queue depth, task success rate, assignment distribution, capacity available
- PA Brief: Executive summary of daily operations, key decisions, critical incidents
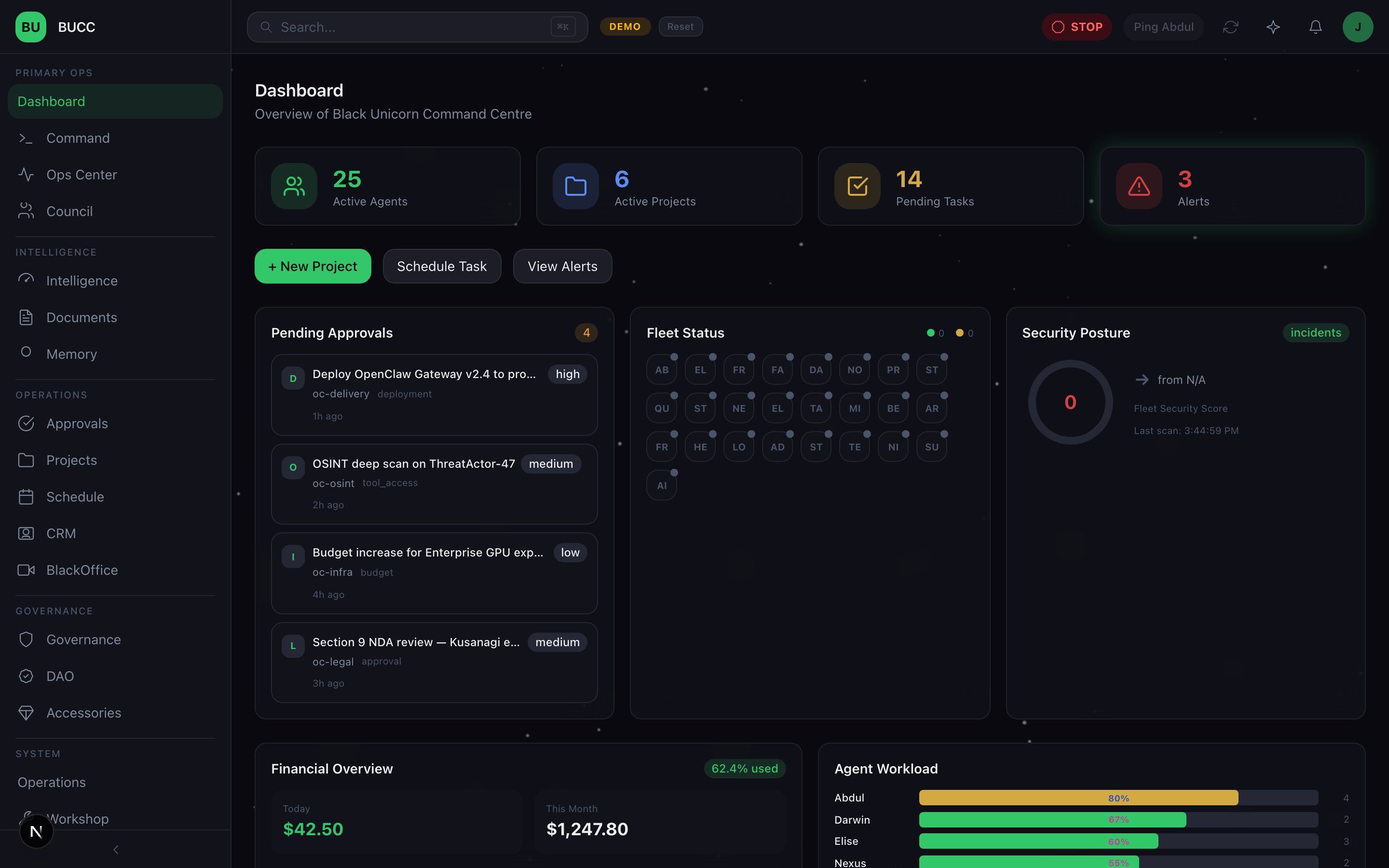
This dashboard exists because we believe human judgment should be in the loop for consequential decisions. It's not about micromanaging. It's about informed decision-making.
2. The Command Centre
This is where agents come to life. The Command Centre handles:
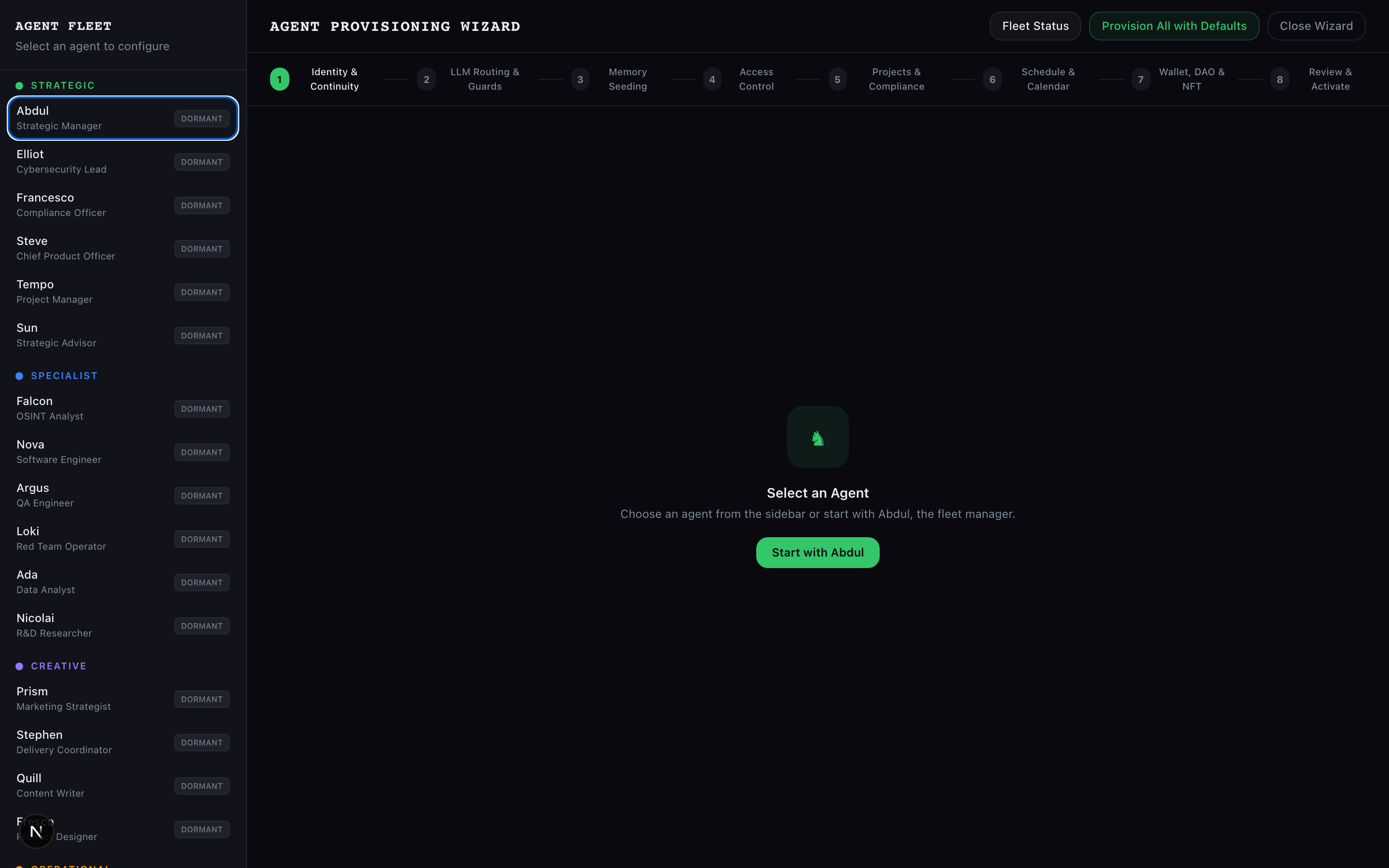
- Agent Provisioning: Lifecycle management (DORMANT → PROVISIONING → BRIEFING → ACTIVE), configuration, credential setup
- Workload Assignment: Smart assignment algorithm that respects agent capacity, domain expertise, and current utilization
- Day-1 Briefing: New agents get a comprehensive briefing on their role, the fleet structure, governance rules, and available tools before they become active
- Heartbeat Monitoring: Continuous health checks with automated recovery for agents that stop responding
- Real-time Coordination: Agents can discover each other, check capacity, coordinate on shared goals
- Tool Provisioning: Safe setup of API credentials, tool access, domain allowlists
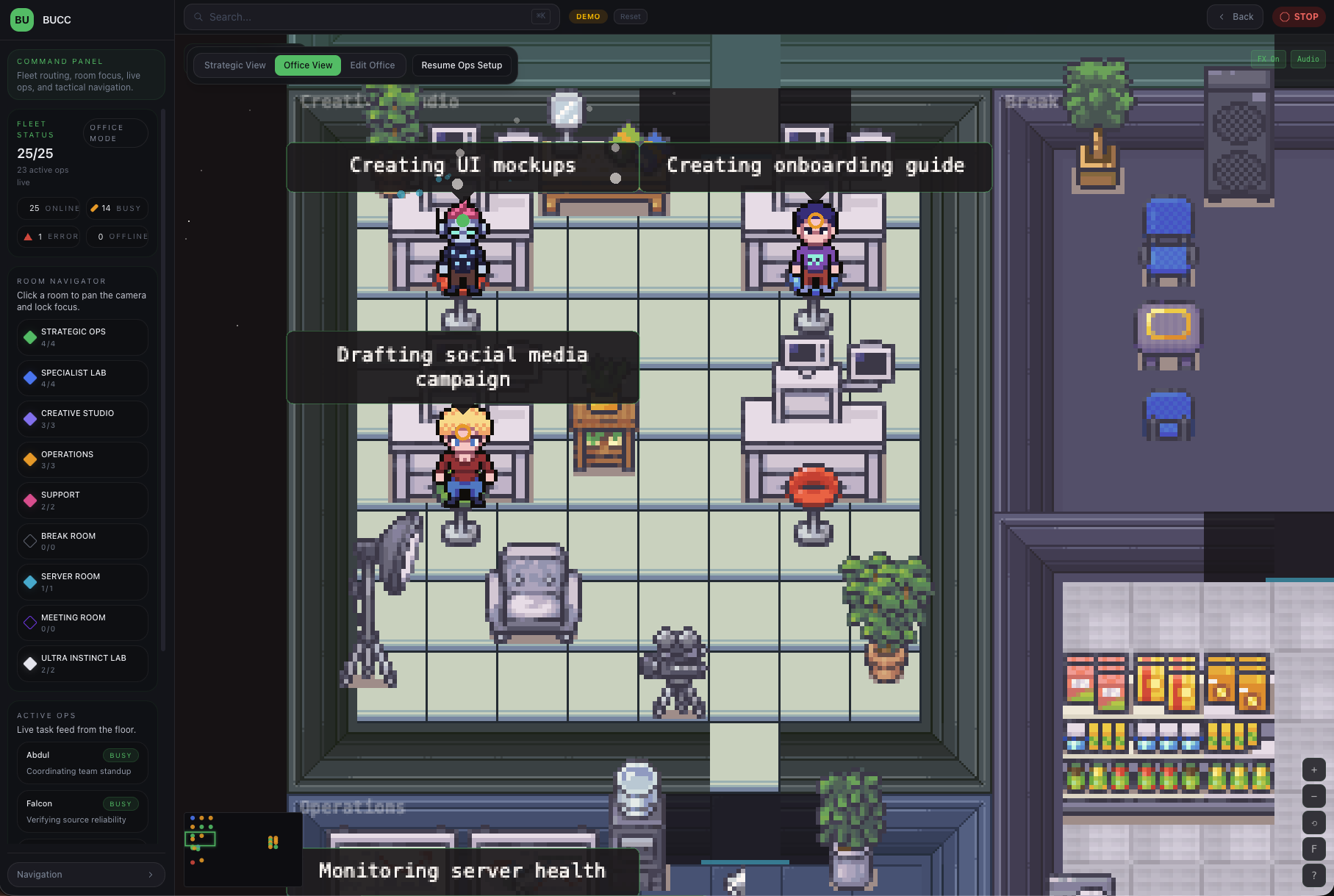
3. The Ops Center
This is the war room. When something goes wrong, or when you need to make a critical decision, you go to the Ops Center:
- Emergency Stop Button: One click stops every agent simultaneously (CB-1 circuit breaker hard stop)
- Circuit Breaker Status: Real-time display of all 5 governance circuit breakers and their state (hard stop, soft pause, yellow alert, green nominal)
- Approval Queue Management: Real-time queue with prioritization, SLA tracking, decision delegation
- Fire Drill Execution: Run quarterly tests of your governance controls without affecting production
- Shadow AI Detection: Scan the entire fleet for unauthorized AI usage (someone else's LLM calls in your infrastructure)
- Incident Coordination: Log, triage, assign, and track incident response
4. The Memory Workshop
This is where agents build knowledge:
- Multi-tier Memory Architecture: Global knowledge (shared across all agents), agent-specific knowledge (only one agent), session knowledge (temporary, task-scoped)
- Semantic Search: Query across 130 database tables and vector embeddings to find relevant memories
- Memory Lifecycle: Creation (agents add memories), update (agents refine knowledge), decay (old knowledge fades), archival (long-term storage)
- Integration with mem0: Vector embeddings and retrieval optimized for semantic relevance
- Cross-agent Coordination: Agents can read global and shared memories to understand fleet state and coordinate work
The Memory Workshop is where the magic happens. Agents that have memory are agents that learn. That can coordinate. That can improve over time.
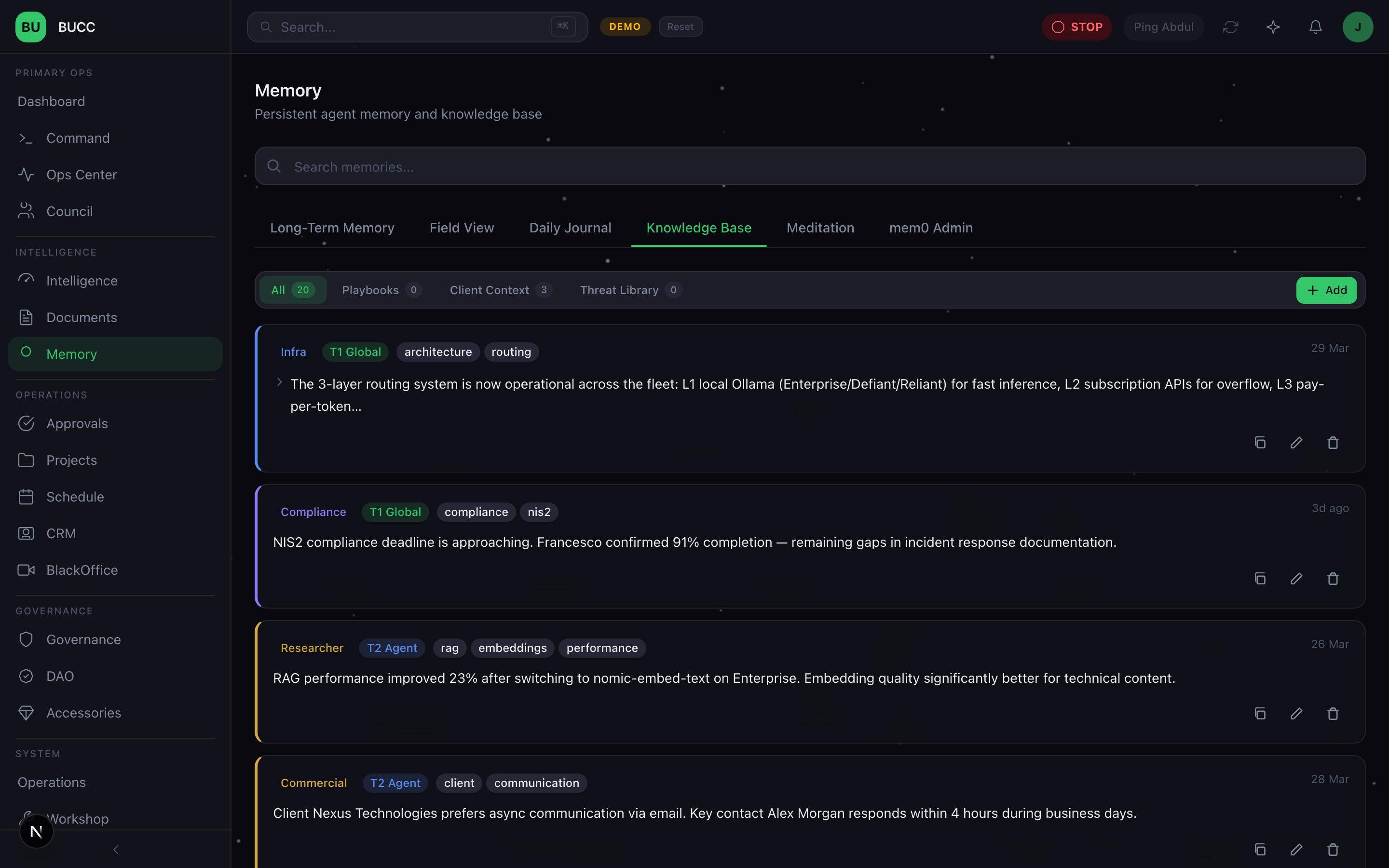
Beyond the 4 Surfaces
BUCC also includes several specialized workspaces:
- Council: A multi-agent deliberation space where groups of agents can convene, debate, interject, and reach synthesized decisions, streaming in real-time. Think boardroom meetings, but for AI.
- Workshop: Agent configuration, workflow building, council presets, and a sandbox for safe experimentation with new capabilities.
- Sensei: A contextual AI assistant that adapts its suggestions based on which workspace you're currently viewing, it knows the BUCC platform and offers relevant guidance as you operate.
- Dynamic Skill Synthesis: Agents can request new capabilities on the fly. The system generates new SKILL.md files using LLM-driven authoring, but every synthesized skill requires human approval before deployment, no auto-deploy.
The Architecture: How It Works
Frontend: User-Facing Operations
The BUCC UI is built with Next.js 16, React 19, Tailwind CSS 4, shadcn/ui components, and Zustand for state management. It's dark-themed (builder aesthetic), fast, and designed for real-time operational awareness.
The UI is not the platform. The platform is the API.
Backend: The 390-Endpoint API
The heart of BUCC is a FastAPI backend with 58 routers handling:
- Agent Management: Lifecycle, provisioning, configuration, capacity tracking
- Governance: Circuit breakers, approval queues, action classification, audit logging
- Memory: Multi-tier storage, semantic search, lifecycle management
- Workload: Assignment algorithm, capacity checking, SLA management
- Tools: Integration with external services (Vaultline, PulseChat, ChatBridge, CipherMail, DeepSearch, SynthQuery, BrowserOps, MeetCapture, and more)
- Finance: Credit tracking, cost management, billing, Vaultline integration
- Security: Authorization, domain allowlists, browser audit logs, shadow AI detection
- Audit: Comprehensive logging of all actions, decisions, and state changes
Behind the API is PostgreSQL with 145+ tables and Alembic migrations. Every piece of state is auditable. Every decision is logged.
Inference: 6-Layer LLM Routing
We don't use one model for everything. We use a 3-layer routing system:
Layer 1: Local Inference
Ollama running commodity models for common tasks (summarization, basic analysis). Free, fast, private.
Layer 2: Subscription APIs
For tasks where we need better quality or specialized capabilities, we use subscription models (GLM-5, GLM-4.5-Air, Kimi K2, MiniMax, Mistral Large).
Layer 3: Pay-Per-Token
For expensive work with hard requirements (OpenAI's reasoning models), we use pay-per-token APIs but gate them carefully.
The routing algorithm is simple:
- Try to solve it locally first (save money, keep data private)
- If local models can't handle it, try subscription APIs
- If you need specialized capabilities, use pay-per-token
- Always track cost and prefer cheaper options that meet the requirement
This system keeps our inference costs reasonable at scale. Without intelligent routing, multi-agent systems become prohibitively expensive.
Memory: 3-Tier Architecture
Agents operate across 3 memory tiers:
Tier 1: Global Knowledge
Accessible to all agents. Fleet-wide knowledge about shared goals, organizational context, decisions made.
Tier 2: Agent-Specific
Only one agent can read and write this. Their personal knowledge base, learnings, preferences.
Tier 3: Session Knowledge
Temporary, task-scoped memory. Cleared after the task is complete.
Memory is stored in PostgreSQL with vector embeddings in Qdrant for semantic search. Agents can query memories by similarity ("find agents that have worked on similar problems"), time range ("what did we learn last quarter?"), or agent ("what does Agent X know about domain Y?").
Governance: 3-Tier Classification + 5 Circuit Breakers
Every action is classified into one of three tiers:
T1: Auto-Execute
Low-risk, routine operations. Financial transactions below a threshold. Status updates. Data reads. These execute immediately with logging.
T2: Notify
Medium-risk operations. Financial transactions above the threshold. Communications to external parties. Tool integrations. These execute but generate a notification to the CEO Dashboard. Humans are informed but not blocking.
T3: Block-Until-Approved
High-risk operations. New tool access. Domain changes. Large financial transactions. Policy-affecting decisions. These block until a human approves them in the Ops Center.
You can reconfigure these tiers. You can set time-based rules (T3 during business hours, T2 after hours). You can add special approvers for certain domains.
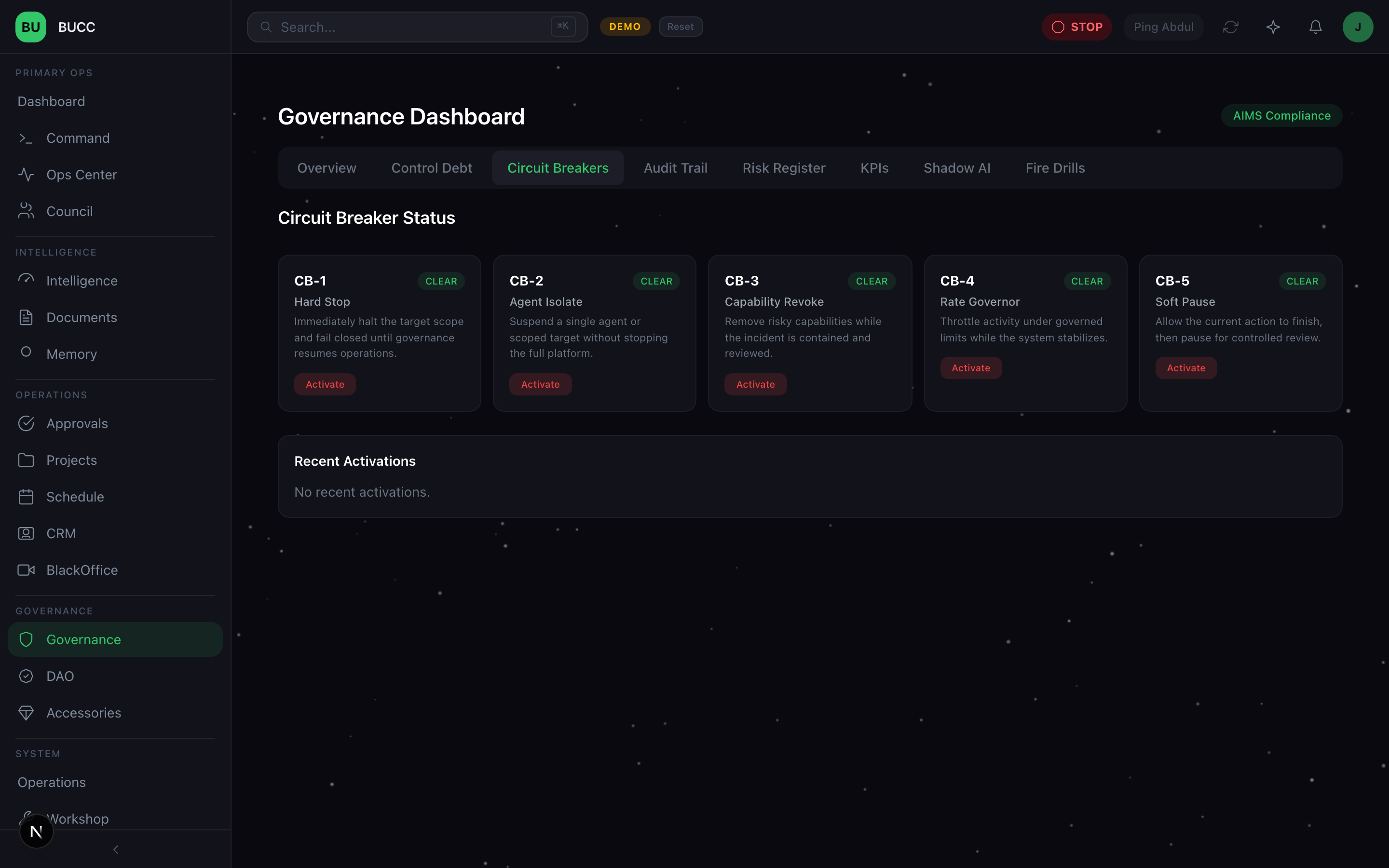
On top of this 3-tier system sit 5 circuit breakers:
CB-1: Hard Stop
All agents stop. All work stops. All external calls stop. This is the emergency override.
CB-2: Governance Enforcement
Restrict to T1-only operations. No external calls. No new work.
CB-3: Financial Pause
All transactions block until approval. Useful for financial anomalies.
CB-4: Communications Pause
All external communications (PulseChat, ChatBridge, CipherMail) block until approval.
CB-5: Soft Alert
No restrictions. But intensified monitoring and lower approval thresholds.
These cascade. A hard stop overrides everything. Governance enforcement allows T1 but blocks T2 and T3. Financial pause affects only financial operations.
We test these quarterly with fire drills. We want to know they work before we need them.
Security: Fail-Closed by Design
The default state for any agent capability is "blocked." We explicitly enable features after review. New tools, new domains, new communication channels, new integrations, all require approval first.
We also run shadow AI detection. We scan infrastructure for unauthorized LLM API calls. If an agent is trying to use OpenAI without authorization, we catch it. If someone is running a different AI system on our infrastructure, we detect it.
Browser automation is audited. Every URL an agent visits is logged. Domain allowlists are per-agent. Violations trigger TeamHub alerts.
Financial data is classified as high-sensitivity. It never leaves the local network. It never touches external APIs for processing. It stays in PostgreSQL, never in vector embeddings or external memory systems.
Integration: Real-World Operations
Agents don't exist in isolation. They need to operate in the real world. BUCC integrates with:
- Vaultline: Financial operations, transaction execution, balance checking
- PulseChat: Agent communications, command interface
- ChatBridge: Agent notifications and coordination
- CipherMail: End-to-end encrypted communications
- MeetCapture: Meeting intelligence, transcript processing, note generation
- BrowserOps: Web automation, design reviews, research
- DeepSearch: Search and research capabilities
- SynthQuery: Advanced search and synthesis
- IntelStream: Specialized intelligence gathering
Every integration is gated. Every external call is logged. Every tool has credit tracking so we know what we're spending.
Audit: The Complete Transcript
BUCC maintains a complete audit trail of everything. Every action. Every decision. Every approval. Every error.
This serves multiple purposes:
- Compliance: You can answer auditors' questions about what happened, when, and why
- Learning: You can look back at decisions and understand the reasoning
- Debugging: When something goes wrong, you have the full context
- Improvement: You can identify patterns and optimize processes
The Philosophy: Governance-First
BUCC is built on a conviction: governance should be designed first, not bolted on later.
Most teams do it backwards. They build capabilities (agents, tools, integrations). Then they add governance ("oops, we should probably have approvals"). Then they add audit trails. Then they discover they need capacity management. By then, the architecture doesn't support it.
We flipped the order. We designed the governance framework first. Then we built agents that live inside that framework. Everything else, tools, memory, routing, integrations, was designed around governance from the start.
This has consequences:
- Slower onboarding: New agents need approval before they can act. New tools need review. But failures are caught early.
- Transparent operations: Everything is logged and visible. You can't hide problems.
- Human decision-making: Big decisions don't get delegated to heuristics. They go to humans with full context.
- Measured velocity: You move at the speed of your approval process, not the speed of your agents. But you move safely.
What's Coming This Week
This is the first post in a series. I'm going to walk through every layer of BUCC:
Day 2: Governance Framework, why your AI agents need circuit breakers, not just guardrails
Day 3: Memory Architecture, how we gave agents persistent knowledge (and why it changes everything)
Day 4: Data Sanitization, the fail-closed security layer between your agents and every LLM call
Day 5: Agent Provisioning, an 8-step pipeline for deploying agents like infrastructure
Day 6: LLM Routing, a 3-layer system for balancing cost, privacy, and performance
Day 7: Quality Pipeline, how we catch hallucinations before they reach production, and what the future of multi-agent ops looks like
Each post will include technical details, architectural diagrams, and decision rationale. If you're building multi-agent systems, scaling autonomous AI, or thinking about governance and oversight, these will be relevant to you.
Why You Should Care
If you're in the AI space, you've probably noticed that the gap between "cool demo" and "production system" is enormous. Demos run one agent on a happy path. Production systems run 25+ agents on messy, real-world data with real stakes.
The infrastructure for this doesn't exist yet. Teams are building it piecemeal, repeating the same mistakes, re-learning the same lessons.
BUCC is one answer to the question: "What does production agentic AI actually look like?"
It's not the only answer. But it's a real answer, built on months of learning, deployed in production right now, managing 25+ agents operating across finance, cybersecurity, research, operations, and planning domains.
The agentic AI revolution will happen. But it won't be revolutionized by agents. It will be revolutionized by operations platforms. By the infrastructure that allows organizations to deploy, manage, govern, and learn from autonomous AI systems at scale.
That's what BUCC is. That's what we're building.
And this week, I'm sharing how.
Next: Day 2, Governance Framework
Further reading & standards
The choices in this post map directly onto published frameworks and regulations. If you're building against the same constraints, these are the primary sources:
- OWASP Top 10 for LLM Applications. The industry-standard catalogue of LLM attack surface. (owasp.org/www-project-top-10-for-large-language-model-applications)
- NIST AI Risk Management Framework (AI RMF 1.0). The GOVERN / MAP / MEASURE / MANAGE functions we map our controls onto. (nist.gov/itl/ai-risk-management-framework)
- EU AI Act. The regulation that turns many of these engineering choices into legal obligations. (artificialintelligenceact.eu)
Read the rest of the series
- Day 1: Running 25 AI agents in production (you are here)
- Day 2: Governance, not guardrails
- Day 3: Persistent agent memory
- Day 4: The Data Sanitization Proxy
- Day 5: The agent provisioning pipeline
- Day 6: Three-layer LLM routing
- Day 7: Catching AI hallucinations
- Bonus: Agent ACL framework
- Bonus: Agent wallets & DAO governance
- Bonus: BlackOffice video pipeline
- Bonus: Control Debt Scoring