Atemi Lab: Testing the Agentic Attack Surface
Testing a single prompt against a single model is a solved problem. Testing a chain of tool calls, a multi-turn agent loop, and a web of MCP servers that can rewrite each other's context is a different problem entirely. We built Atemi Lab for that. Seven workspaces, four attack modes, 17 active tools, and a real agent harness. Day 4 of the DojoLM builder's journal.

Everyone on AI Twitter has been talking about MCP exploits and agent-to-agent compromise for the last six months. The conversation is correct. The tooling has not caught up.
"MCP is a known problem. There is no way to test the MCP servers in the stack."
"The agent calls three tools in sequence. There is no way to fuzz the chain."
"A multi-turn agent runs in production. The evaluation loop runs once a release, and it is a script someone wrote last year."
"A new tool landed last week. There is no way to know if that tool is a new attack surface."
"The red team uses ChatGPT to brainstorm adversarial prompts. That is the agentic testing program."
Testing a single prompt against a single model is a solved problem. Run the payload, read the response, score the result. Done. Testing a chain of tool calls, a multi-turn agent loop, and a web of MCP servers that can rewrite each other's context is a different problem entirely. It has different failure modes. It needs a different lab.
Yesterday the Armory opened. Today Atemi Lab opens, the workspace where DojoLM stops testing single-turn prompts and starts testing agentic loops, tool calls, and MCP servers end to end.
Why Agents Need a Different Lab
An agent is not a prompt. Attacks on agents happen at three boundaries that a prompt scanner never sees.
The tool call boundary. Between the agent's decision to call a tool and the tool's execution is an argument-serialization step. Attacks here target argument types, escape sequences, injection into structured fields, and schema reconstruction from error messages.
The transport boundary. Between the agent and an MCP server is a JSON-RPC protocol over HTTP, WebSocket, or stdio. Attacks here target protocol framing, handshake abuse, out-of-order messages, and the transport layer's error handling.
The context reconstruction boundary. Between turns in a multi-turn conversation, the agent rebuilds its context from memory, history, and retrieved documents. Attacks here target the rebuild itself, poisoning earlier turns to change how the agent interprets later ones.
A prompt scanner that only sees the final assembled prompt misses all three. The boundaries where the attacks actually happen need direct instrumentation.
Atemi Lab exists for exactly that.
What Atemi Lab Is
Atemi Lab is DojoLM's agentic and MCP attack workspace. Point it at a target agent, a set of tools, a protocol (HTTP, JSON-RPC, MCP, or WebMCP), and an attack mode, and it runs structured adversarial tests end to end. Not a prompt scanner with extra steps. A real agent harness with instrumentation at every boundary that matters.
Seven workspaces. Four attack modes. 17 active tools this week. Full integration with the Armory, the DNA graph, and Sengoku campaigns. Everything it discovers flows back into the library as candidate fixtures.
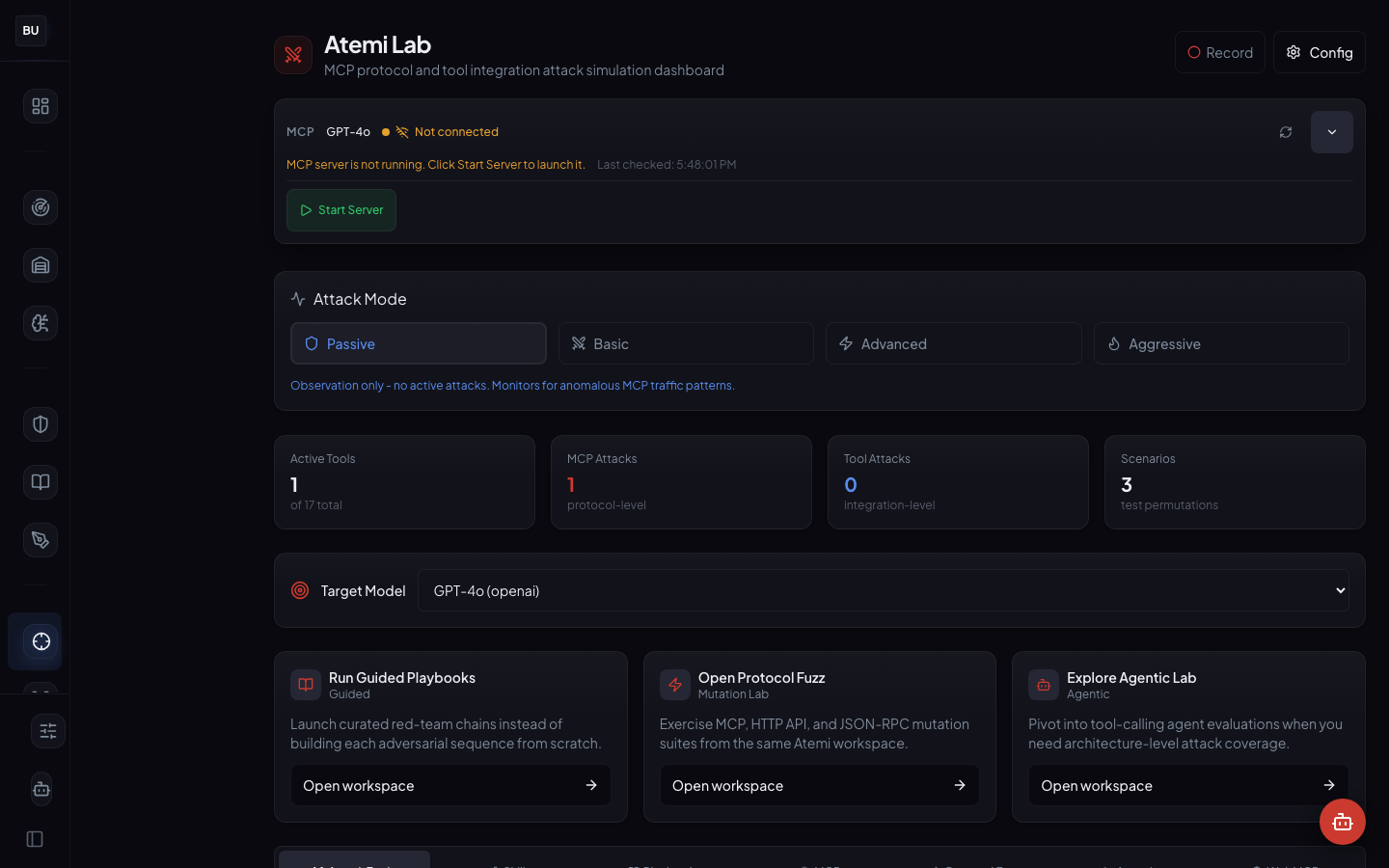
The numbers
- 7 workspaces: Attack Tools, Skills, Playbooks, MCP, Protocol Fuzz, Agentic, WebMCP
- 4 attack modes: Passive, Basic, Advanced, Aggressive
- 17 active tools in the current tool library, grouped by attack skill
- MCP as a first-class target with its own workspace, its own fuzzer, and its own fixture subset
- Full Armory integration for known-pattern testing
- Full DNA graph integration for lineage tracking of novel findings
- Playbooks are declarative and versioned, not shell scripts
- Every tool runs sandboxed, a rogue tool cannot touch the rest of the workspace
The lab is a pipeline from wild attack to regression test.
The Seven Workspaces
Each workspace handles a specific attack surface. Building one workspace that tries to do everything produces a workspace nobody uses.
Attack Tools
The main workspace. Connect an MCP server, pick a target, and run attack tools against it. This is where most sessions start. The left panel is the tool library. The center panel is the target configuration. The right panel is the results stream.
Skills
The tool workspace grid. Each card represents a specific attack skill: tool argument injection, context reconstruction abuse, chained call exploitation, schema bypass, refusal pattern probing. Skills are grouped by category, and each card shows the fixture count, the tools it uses, and the last run result.
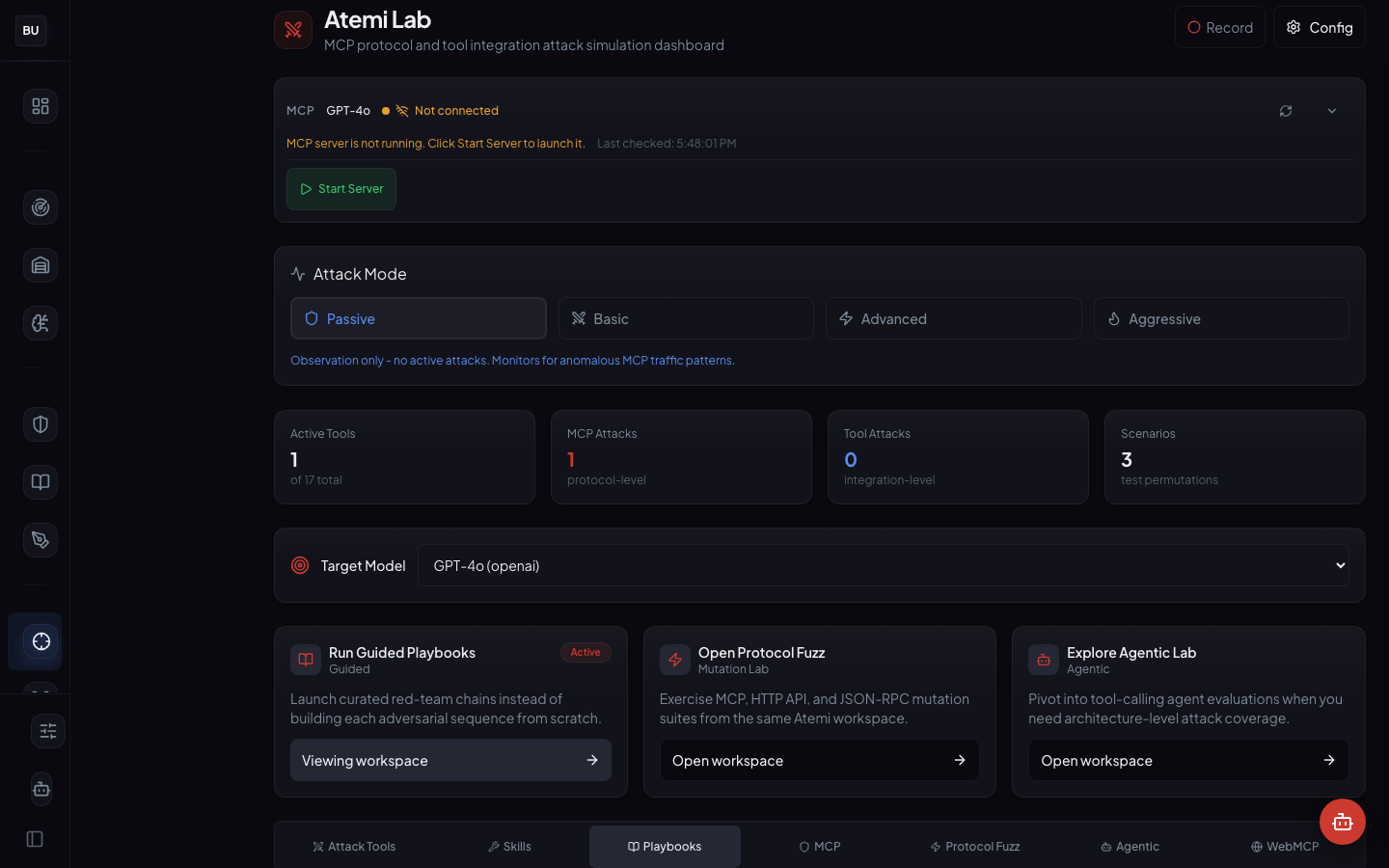
Playbooks
The chain runner. A playbook is a declarative sequence of attack steps with decision points. A playbook can run as a single unit, and the runner evaluates the agent's response at each decision point and branches accordingly.
Playbooks turn one researcher's attack chain into a reusable test anyone on the team can run. They can be read, diffed, versioned, peer-reviewed, and shared.
MCP
The connector configuration surface. Point Atemi Lab at any MCP server, describe the auth model, and the workspace is ready to run attacks against it. This workspace is the entry point for any MCP target, whether internal or external.
Protocol Fuzz
The transport-layer workspace. HTTP and JSON-RPC mutation fuzzing for cases where the vulnerability is not in the agent's reasoning but in its protocol handling. Malformed JSON, missing fields, extra fields, wrong types, oversized strings, control characters, out-of-order handshake messages. This is where Atemi Lab finds the bugs that have nothing to do with the LLM and everything to do with the framework wrapping it.
Agentic
The full multi-turn evaluation workspace. Define an objective, a target, and a budget, and the workspace runs an evaluation loop with the chosen orchestrator. This is the workspace for testing the whole agent in a realistic adversarial scenario, not just individual tool calls.
WebMCP
The web-exposed MCP testing workspace. Same protocol surface, different exposure model, different threat surface. An MCP server exposed over a web endpoint has an attacker population an internal MCP server does not. This workspace models that difference.
The Four Attack Modes
Every workspace can run in one of four attack modes. The mode ladder is deliberate. Production agents cannot be slammed with Aggressive fuzzing during business hours. Start Passive, watch telemetry, promote when ready.
Passive
Observes only. Does not send adversarial payloads. It watches the agent's normal traffic and flags anomalies against known patterns. Safe to run against production. This is the mode to use when onboarding a new agent and trying to understand its baseline behavior before any attacking begins.
Basic
Runs known attack patterns from the Armory. This is the "does the agent resist the obvious stuff" mode. Basic mode should be able to run continuously against a production-ready agent and surface zero findings. If Basic mode finds anything on a production agent, that is a regression to fix before touching Advanced.
Advanced
Adapts its attacks based on the agent's responses. If a refusal pattern surfaces, Advanced rephrases and retries. If a tool schema becomes visible through an error message, Advanced targets the schema's edges. Advanced is where most of the novel findings come from on a mature agent.
Aggressive
Pushes the loop until the agent breaks or the budget runs out. Aggressive is for canary environments, not production. It is also the mode most likely to surface novel findings that become new Armory fixtures. Aggressive runs against a staging copy of the agent, with a hard budget, and is expected to find something every week.
The modes are a ladder, not a menu. Nobody starts at Aggressive.
Principles Behind the Lab
Protocol-aware, not prompt-aware
An agent is not a prompt. Attacks on agents happen at the tool call boundary, the transport boundary, and the context reconstruction boundary. A prompt scanner that only sees the final prompt after the agent has assembled it misses most of the interesting attack surface. Atemi Lab instruments all three boundaries, records the raw traffic, and scores each boundary separately.
MCP as a first-class target
MCP is the fastest-moving agentic protocol this year and one of the most exposed. It has its own workspace in Atemi Lab, its own fuzzer, its own playbook library, and its own fixture subset in the Armory. Atemi Lab treats MCP as a target that deserves dedicated attention, not as one more protocol to support inside a generic fuzzer.
Playbooks are declarative
A playbook is not a shell script. It is a declarative chain with typed steps, decision points, and branching logic. Playbooks can be read, diffed, versioned, and peer-reviewed. A shell script cannot. This matters because a playbook is documentation of an attack strategy, not just an execution artifact. When the researcher who wrote the playbook moves on, the next researcher can still read it, understand it, and extend it.
Tools are isolated
Every active tool in Atemi Lab runs in a sandboxed execution context. A tool that goes rogue cannot touch the rest of the workspace. This sounds obvious. It is not obvious in most agentic testing frameworks on the market today, where a compromised tool can propagate state into every other tool in the same session.
Everything writes back to the Armory
A novel payload surfaced by Atemi Lab that gets past the existing fixtures becomes a candidate new fixture. Every candidate goes through the same ingestion pipeline as any other fixture: tag, assign a severity, link to a scanner pattern, run the regression suite, merge. The lab is a pipeline from wild attack to regression test. Nothing stays in Atemi Lab. Findings move downstream or they are not findings.
The Tool Library
17 active tools is the current count this week. The tool set includes:
- Prompt injection probes that target the agent's assembled context
- Tool schema introspection that reconstructs hidden tool definitions from error messages
- Argument fuzzing that targets the tool call boundary with malformed arguments
- Context reconstruction tests that probe how the agent rebuilds state between turns
- MCP handshake abuse that targets the initialization and session-id handling
- Tool chaining exploits that build attacks across multiple tool calls
- Refusal bypass probes that test the strength of the agent's refusal patterns
- Schema bypass that targets structured-output enforcement
- Privilege escalation probes that test agent-to-agent boundaries
- Timing attack tools for side-channel discovery in tool execution
Each tool has its own configuration surface, its own documentation, and its own set of Armory fixtures it can run.
Tools are plugins. Adding a tool is a config change plus an implementation module. Atemi Lab ships with a stable base set and the ability to extend, because the attack surface is always moving and the tool library has to move with it.
The MCP Fuzzer
MCP is a JSON-RPC protocol over a chosen transport. The MCP fuzzer mutates the protocol messages at multiple levels at once:
- JSON structure mutation: missing fields, extra fields, wrong types, deeply nested payloads, self-referential structures
- Content mutation: oversized strings, control characters, encoded payloads, non-UTF-8 byte sequences
- Semantic mutation: valid syntax but impossible values (negative lengths, future timestamps, out-of-range enums)
- Handshake mutation: out-of-order messages, missing initialization, duplicate session ids, stale tokens
Every mutation is tracked. Every response is logged. Every interesting deviation surfaces as a candidate finding. The fuzzer does not fire and forget. It records the full session, the exact mutation sequence, the agent's reaction, and enough context to reproduce the finding.
The Playbook Library
The current playbook library includes chains for:
- Tool enumeration that systematically discovers what tools an agent has access to
- Context reconstruction that rebuilds prior conversation state from retrieved fragments
- Schema bypass that works around structured-output constraints
- Agent loop abuse that exploits the multi-turn reasoning loop
- Handshake hijacking on MCP servers with weak session handling
Each playbook is authored by a specific researcher, versioned, and linked to the DNA graph so related playbooks surface together. Playbooks turn one researcher's attack chain into a reusable test that anyone on the team can run without recreating the researcher's mental model from scratch.
Why This Matters Right Now
The teams shipping agentic products are running multi-step loops in production with tools that can read files, send email, call other agents, execute code, and touch external systems. The blast radius is no longer a single hallucinated response. It is a chain of real actions in real systems. A single compromised tool call can propagate through the entire agent's state and trigger real consequences in downstream systems.
Testing that chain is not optional. The only question is whether the lab gets built or whether the failure happens in production. Atemi Lab is the lab side of that choice, and the architecture is shared openly because every team shipping an agent is about to face the same problem, and the tooling gap is real.
The Principles, In Summary
- Instrument the boundaries, not just the prompts. The attacks live at the boundaries.
- Respect the mode ladder. Do not start at Aggressive.
- Treat MCP as its own target class. It moves fast enough to deserve dedicated workspaces.
- Write playbooks as declarative chains, not shell scripts. Playbooks outlive their authors.
- Feed everything back to the Armory. A finding that stays in the lab is a finding that disappears.
What Is Next
Tomorrow, Day 5, the seat switches from offense to defense and Hattori Guard opens. Four modes of runtime defense, 250 events processed, 127 blocks, full audit trail, and the same Haiku Scanner engine as the rest of the platform.
The deep dive will walk through the mode ladder (Shinobi, Samurai, Sensei, Hattori), the hardening pipeline, the audit log structure, and why running the same engine for both testing and runtime is the only way to avoid drift between what the lab catches and what production catches.
See you there.