Control Debt: Quantifying Whether Your AI Governance Actually Works
Technical debt is code that's fast to ship and slow to maintain. Control Debt is governance you skipped, guardrails you bypassed, approvals you auto-clicked. We built a scoring system that makes it visible before it compounds into a breach.

You already know technical debt. Code that's fast to ship and slow to maintain. Every team has a rough intuition for when it's getting out of hand, the velocity drops, the bugs pile up, the refactor meeting shows up on the calendar.
There's a second debt nobody measures. We call it Control Debt.
The diagnosis: governance is a metric-free zone
Control Debt is the governance you skipped to ship faster. The security review that turned into a thumbs-up emoji in a team-chat channel. The guardrail you muted because it was too noisy. The tool access you granted without a second pair of eyes because the approval queue was backed up. The audit cycle you postponed because nothing was on fire this week.
Each of those feels harmless in isolation. That's the problem. Technical debt at least makes its presence felt, the build gets slower, the tests get flakier. Control Debt is silent. It accumulates in the audit log you never read, in the approvals you never challenged, in the three hundred auto-approved decisions that nobody noticed were all from the same agent.
Most teams running agents have no number for this. They have a feeling. They have "governance posture." They have "we think it's fine." When something goes wrong, the post-mortem always finds the same thing: the control was on paper but nobody was looking.
We asked: what would it take to quantify governance the way we quantify test coverage?
What we built: Control Debt Scoring
Control Debt Scoring (CDS) is a per-agent, evidence-based metric. It's not a survey. It's not a self-assessment. It's computed directly from the audit trail the fleet already emits on every action.
The formula we run in production:
CDS = sum(
unreviewed_decisions × 10 +
bypassed_guardrails × 25 +
tool_access_violations × 15 +
memory_access_anomalies × 20 +
missed_audit_cycles × 5
)Every term is a real column in a real table. Every weight is tunable. Every input is timestamped, attributable, and reviewable.
unreviewed_decisions, decisions an agent made that were taggedAUTO_APPROVEDwithout a second reviewer. Every T2/T3 action carriesreview_status,review_depth,review_timestamp, andreviewer_id. Missing reviewer = +10.bypassed_guardrails, cases where a guardrail fired and was overridden. Overrides are legitimate. Unreviewed overrides are debt. +25 because bypasses are the highest-signal event we track.tool_access_violations, attempts by an agent to touch a tool outside its ACL row. The action fails closed (see Bonus: Agent ACL framework), but the attempt itself is evidence of a misconfiguration or a drifted scope. +15.memory_access_anomalies, reads or writes across memory tiers that don't match the agent's historical pattern. +20 because unusual memory access is the first indicator of a compromised or misaligned agent.missed_audit_cycles, scheduled governance reviews (weekly fleet sweep, monthly ACL reconciliation, quarterly fire drill) that slipped. +5 each, because the cost is small but the signal that the process is eroding is big.
The dashboard
CDS lives in the CEO Dashboard as a dedicated tab. Four views:
- Per-agent CDS trend. A line chart per agent over the last 30 days. You can see immediately which agent's score is drifting upward.
- Fleet-wide CDS gauge. One number for the whole fleet. It's the governance equivalent of a car's oil pressure light.
- Debt breakdown by type. Which term in the formula is driving the score? Unreviewed decisions? Bypassed guardrails? The breakdown tells you where the leak is, not just that there is one.
- Forecast. A simple linear projection: if the current trajectory holds, when does the fleet hit the next threshold?
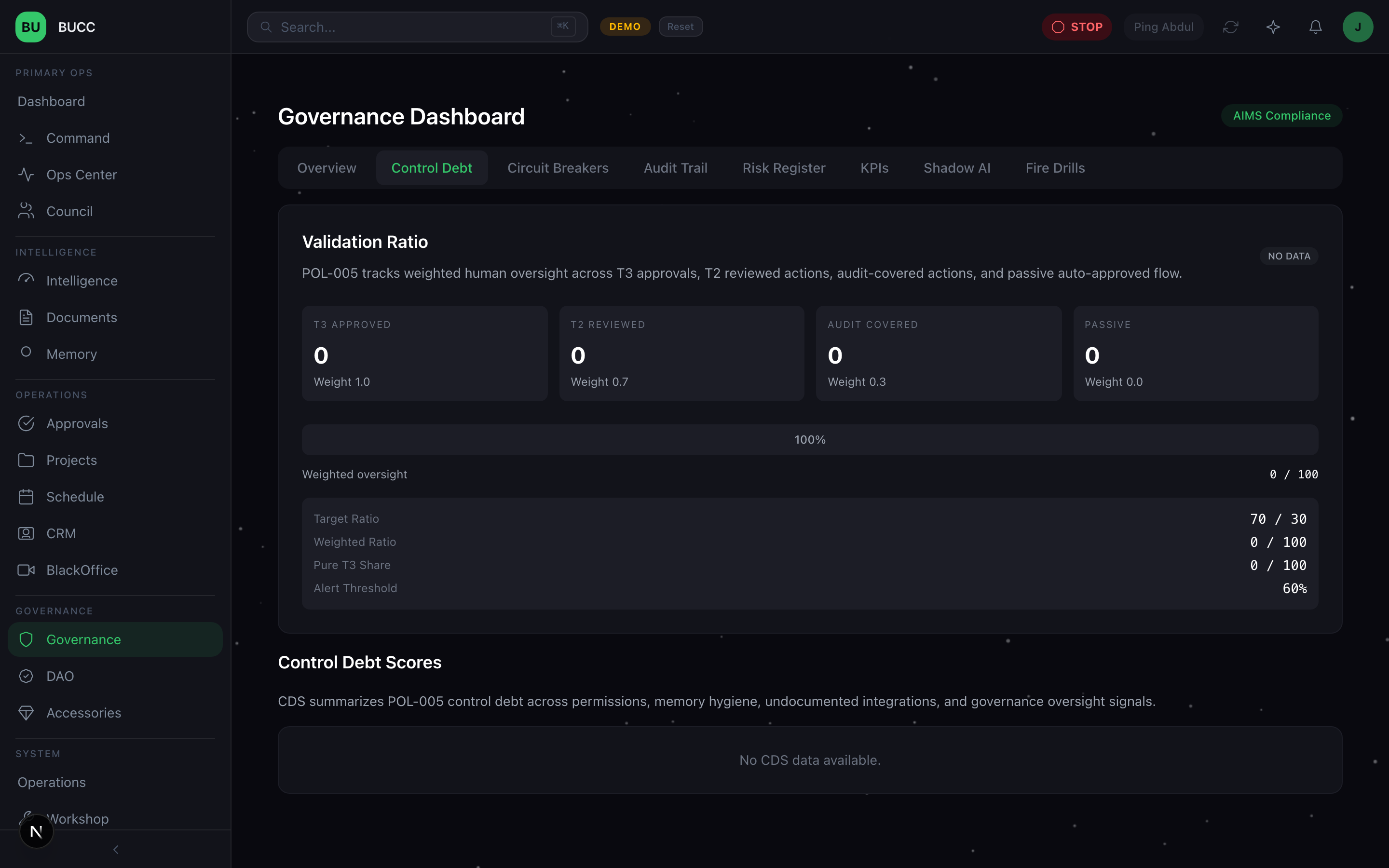
The thresholds
We run four bands:
- Healthy, 0 to 50. Agents are well-governed. This is where most weeks land. If you're consistently below 35, the system is working.
- Caution, 50 to 150. You're skipping safety checks somewhere. Not yet dangerous, but the trajectory matters more than the absolute number.
- Danger, 150 to 300. Governance is breaking down. One or more terms in the formula is out of control.
- Critical, 300+. You have lost sight of what your agents are doing. Circuit breakers should already have engaged.
At CDS ≥ 250, BUCC automatically engages circuit breakers without human intervention:
- All agents move to
MANUAL_REVIEWmode. Every T2/T3 decision requires explicit human approval before it executes. - Tool access is narrowed to the minimum required for each agent's current task.
- New task assignments are rejected until the score drops.
- The Sentinel agent is paged.
The system is not asking for permission. It is declaring: we have lost sight of governance, we are pausing until a human confirms we have it back.
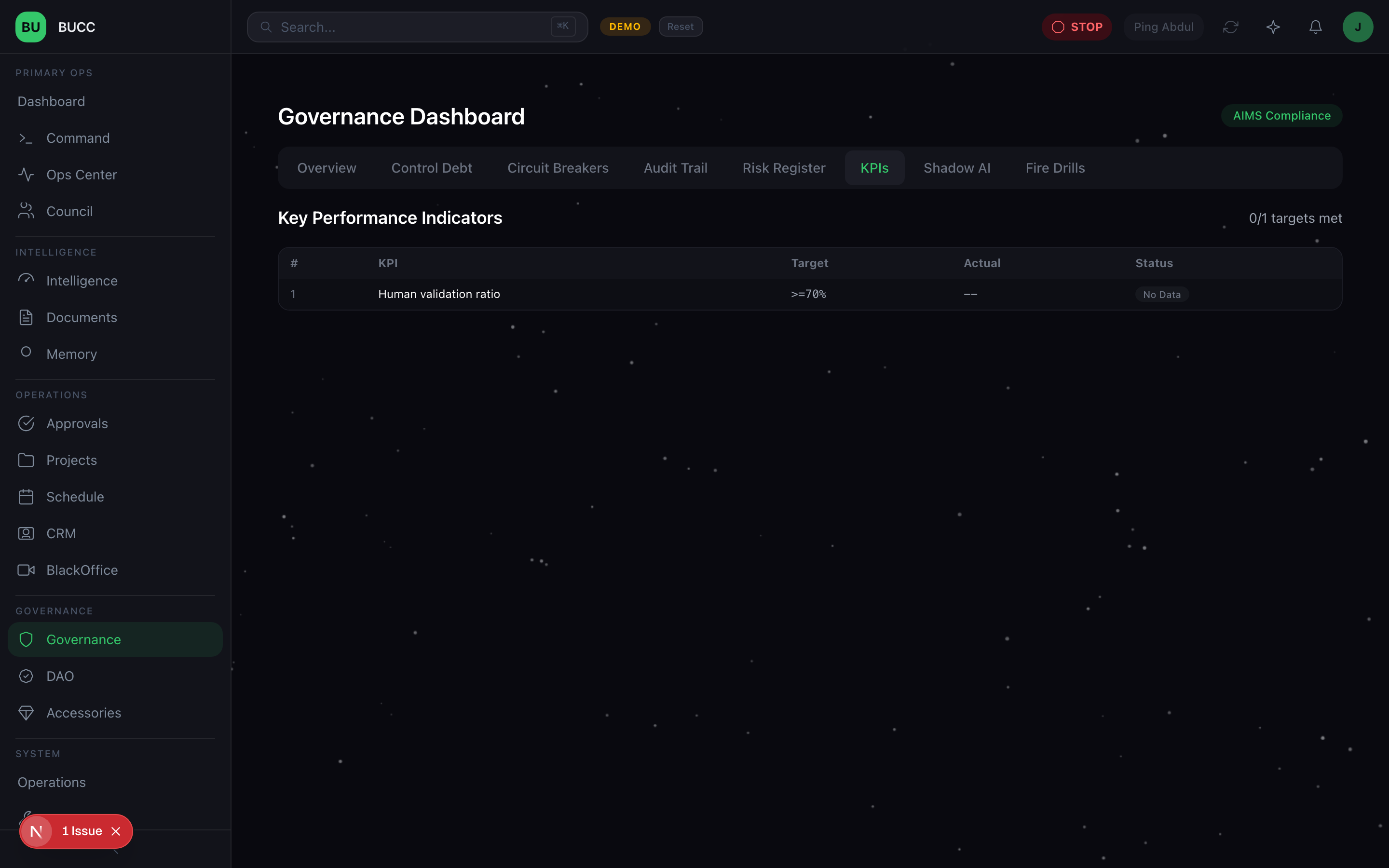
The principles behind the score
Evidence, not self-report. Every input to CDS is a row in the audit log. No agent, no operator, no engineer types a number into the score. If you can't compute it from the trail, it doesn't go in the formula. Governance you can't measure is governance that doesn't exist.
Per-agent, not per-fleet. Aggregate scores hide the one agent that's driving the whole problem. We surface both, the gauge for the fleet and the per-agent trend, but the actionable one is always the individual. You don't fix a fleet. You fix an agent, a process, or a threshold.
Weights are tunable, not sacred. 10/25/15/20/5 are our defaults. They're based on what, in our incidents, correlated best with actual governance failures. Your weights will be different. The important part is that they're explicit, versioned, and reviewable, not hidden in someone's head.
The score triggers behavior. CDS is not a vanity metric. At 250 the system engages circuit breakers. At 150 the Sentinel escalates to human review. At 50 it's a yellow badge on the dashboard. A metric without consequences is decoration.
Debt is a direction, not a level. A score of 40 that's climbing 5 per day is more dangerous than a score of 80 that's flat. The forecast view exists because trajectory is the signal. Flat-but-high means your process has adapted. Rising-but-low means your process is eroding.
A real incident
Two months ago the fleet CDS spiked from ~28 to 85 in under a week. The breakdown view made the root cause obvious on the first click: unreviewed_decisions was doing all the work.
The investigation was quick. The tool approval process had a 24-hour turnaround because a single reviewer was handling every request. Agents needed tools urgently. Engineers started auto-approving to unblock work. Auto-approval meant no second pair of eyes. No second pair of eyes meant every decision landed in the unreviewed bucket. The CDS formula reflected the reality perfectly, a governance process had eroded, and the number went up.
The fix wasn't a tighter control. It was an express approval pathway with a 2-hour SLA for low-risk tools, keeping full review for high-risk ones. The bottleneck cleared, the auto-approvals stopped, CDS dropped to 28 within a week.
That's the loop CDS exists to close: high score → investigate → find the inefficient process → fix the process → score drops. Governance that responds instead of reacting.
The overzealous failure mode
Early on we learned that governance can be too tight. We tried a config where every decision required three approvers. CDS stayed near zero, and the fleet stopped working. Latency on routine tasks exploded. Approval queues backed up. The reviewers burned out. When you make governance expensive enough, people stop following it, and now you have both a backlog and a compliance problem.
So: strict but fair. High-stakes decisions get full review. Routine decisions don't. The formula weights high-stakes terms (bypassed guardrails at ×25, memory anomalies at ×20) much more than low-stakes terms (missed audit cycles at ×5) precisely so that CDS rewards the right kind of rigour.
The analogy that stuck
CDS is to governance what code coverage is to testing. Code coverage asks: how much of our code is actually exercised by tests? CDS asks: how much of our governance is actually exercised by controls?
Both are imperfect proxies. High code coverage doesn't guarantee good tests. Low CDS doesn't guarantee good governance. But both trend over time, both predict breakage when they degrade, and both are vastly better than the alternative, which is "we think it's fine."
If you can't measure it, you can't manage it. If you can't manage it, it compounds silently. And silent compounding is the exact failure mode agentic AI is most vulnerable to.
Further reading & standards
CDS is our attempt to give concrete shape to requirements that already exist on paper. If you're building toward the same standards:
- NIST AI Risk Management Framework, MEASURE function (MS-2, MS-3). NIST asks you to continuously measure the effectiveness of your risk controls. CDS is one such measurement. (nist.gov/itl/ai-risk-management-framework)
- EU AI Act, Article 9 (risk management system). High-risk AI systems must have "a continuous iterative process" for identifying and evaluating risks. A metric that triggers behavior at thresholds is exactly that process in production. (artificialintelligenceact.eu)
- EU AI Act, Article 14 (human oversight). The critical-band auto-engagement of
MANUAL_REVIEWmode is a direct implementation of Article 14's requirement that oversight can "effectively prevent or minimise risks." - OWASP Top 10 for LLM Applications, LLM09: Overreliance. Auto-approval drift is overreliance in slow motion. CDS surfaces it before it matures. (owasp.org/www-project-top-10-for-large-language-model-applications)
Read the rest of the series
- Day 1: Running 25 AI agents in production
- Day 2: Governance, not guardrails
- Day 3: Persistent agent memory
- Day 4: The Data Sanitization Proxy
- Day 5: The agent provisioning pipeline
- Day 6: Three-layer LLM routing
- Day 7: Catching AI hallucinations
- Bonus: Agent ACL framework
- Bonus: Agent wallets & DAO governance
- Bonus: BlackOffice video pipeline
- Bonus: Control Debt Scoring (you are here)
The teams that win with AI agents aren't the ones shipping fastest. They're the ones with clean governance. Measure your control debt. Keep it low. Respond to spikes. Build systems where governance is transparent, not aspirational.
This is a builder's journal, we're sharing the metric because the community needs one that isn't a vibes check.