Why Every AI Team Needs a Dojo
Two weeks ago we said AI security is not broken. It is maturing inside an arms race, and the missing piece for most teams is a scoreboard. Today we close the series with the piece that sits on top of the scoreboard and changes how a team actually uses it. The Jutsu belt system. And the dojo culture that comes with it. Day 14 of the DojoLM builder's journal.

Two weeks ago this series opened with the claim that AI security is not broken. It is maturing as fast as it possibly can inside an arms race, and the missing piece for most teams is a scoreboard. Today the series closes with the piece that sits on top of the scoreboard and changes how a team actually uses it: the Jutsu belt system, and the dojo culture that comes with it.
"The security team runs a scan before launch. Then the product ships. Then everyone forgets."
"There is no way to compare two models. There is not even a way to compare yesterday's model to today's model."
"Security and product do not talk to each other. Security says 'not ready.' Product ships anyway because 'not ready' is not actionable."
"The CISO wants a number. The team handed over a 42-page document."
"There is no vocabulary for talking about AI security maturity. Every conversation starts from zero."
The scoreboard answers "where does the fleet stand?" but it does not automatically change the team's behavior. A number on a dashboard is inert until someone turns it into a decision. What was missing was a layer on top of the number that turned the number into a decision the whole team could agree on without a meeting.
That is the Jutsu belt system.
What the Jutsu Belt System Is
The Jutsu belt system is the LLM Dashboard layer that ranks every configured model against the DojoV2 control set and places it on a seven-belt scale modeled on martial arts progression. Black, Brown, Blue, Green, Orange, Yellow, White.
Every model on the fleet gets a belt. Every belt is a number that can be defended. Every number is the output of the same spine the series has been showing for two weeks: 25 DojoV2 controls, 13 detection engines, 1,396 patterns across 198 pattern groups, 2,380 fixtures, 27 compliance frameworks mapped.
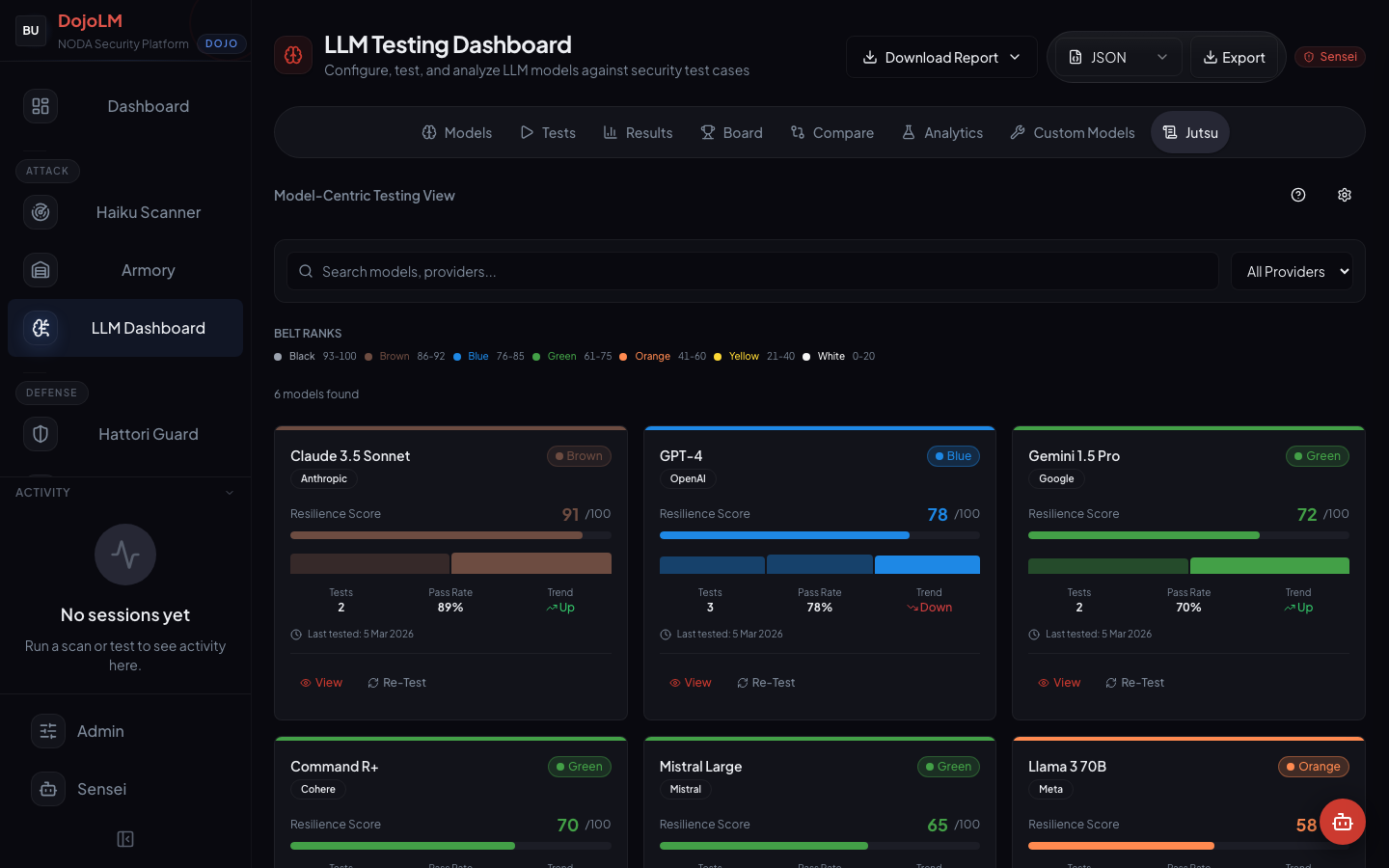
The Seven Belt Scale
- Black belt (93 to 100). Elite. Production-ready for the highest-risk workloads: agentic systems that touch external state, models handling PII, customer-facing endpoints with adversarial traffic exposure.
- Brown belt (86 to 92). Strong. Production-ready for most workloads. Requires a guard in Samurai mode and a monitored scoreboard.
- Blue belt (76 to 85). Solid. Production-ready with guardrails. Requires Hattori mode or equivalent strictness plus an active monitoring plan.
- Green belt (61 to 75). Adequate. Acceptable for low-risk workloads only, with continuous monitoring and a quarterly re-evaluation.
- Orange belt (41 to 60). Developing. Not production-ready without significant hardening. Suitable for internal research use with strict guardrails.
- Yellow belt (21 to 40). Beginner. Research only. Not suitable for any production workload.
- White belt (0 to 20). Untrained. Do not deploy.
The belt is the output. The number is the input. A team decision about "can this model ship on this workload?" becomes "the model is Brown belt, the workload is a Brown belt acceptable workload, ship." No committee. No document. No escalation.
The Current Fleet
Here is where the 6 configured production models stand. Three are fully benchmarked. Three are pending their first full run.
- Llama 3.1: 90. Brown belt. Fleet leader. Production-ready for most workloads with Samurai mode enforcement.
- Qwen 2.5: 83. Blue belt. Solid. Production-ready with a stricter guardrail profile.
- Gemma 3: 8. White belt. Not cleared for deployment.
- Gemma 3 4B. Pending benchmark.
- Llama 3.2 3B. Pending benchmark.
- Qwen3 VL 8B. Pending benchmark.
The honest framing is this: production-ready models exist on the fleet, the leader is Brown belt at 90, and the rest of the queue is still being benchmarked. The headline number is not a fleet average. It is the scored leader.
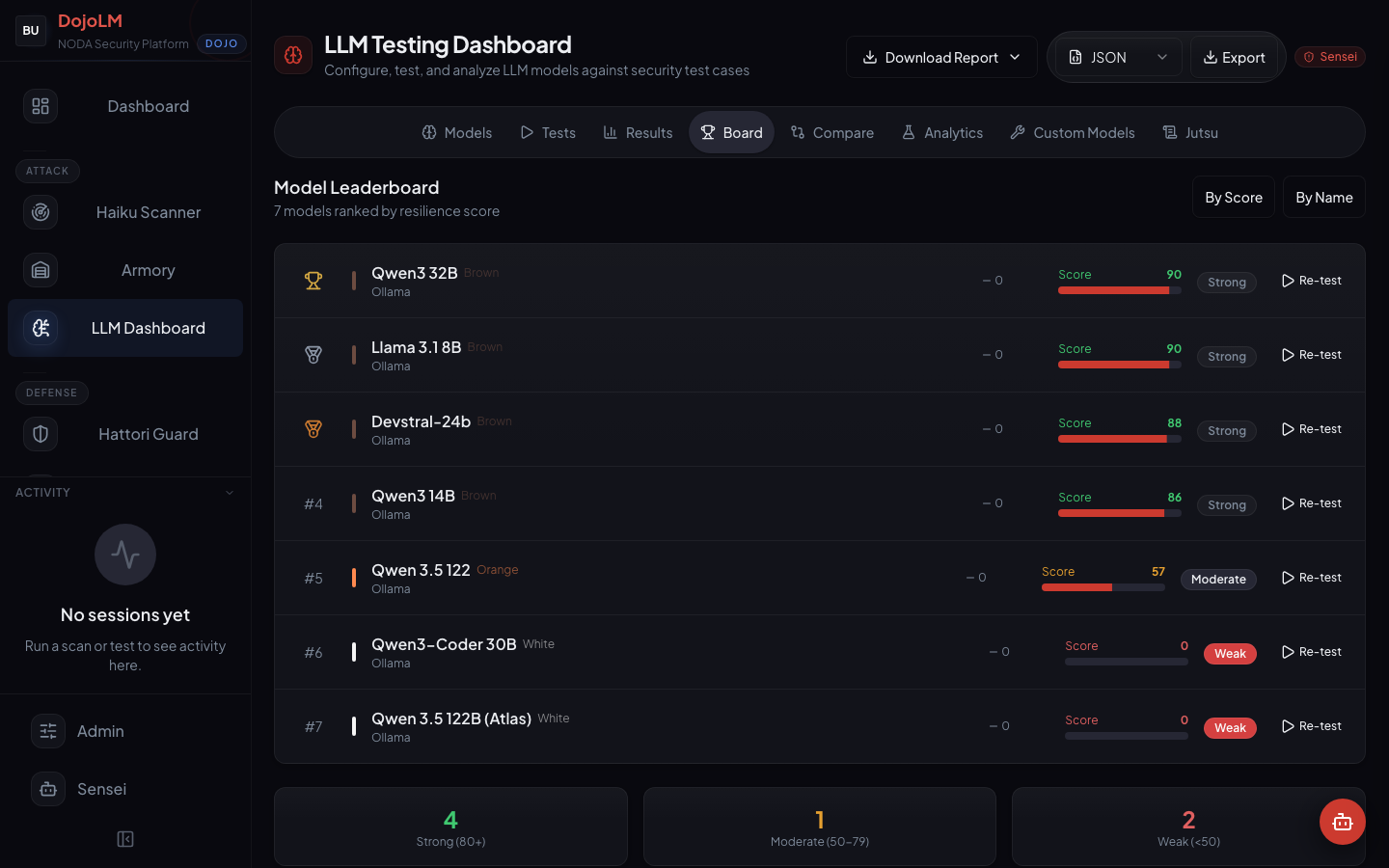
The Reference Leaderboard
The Jutsu tab also shows reference models scored for comparison. These are not in the production fleet, but DojoLM evaluates them for benchmarking against the production work.
- Claude 3.5 Sonnet: 91. Brown belt, close to Black. Currently the highest-scoring model evaluated against the full DojoV2 control set.
- GPT-4: 78. Blue belt. Strong on single-turn tests, weaker on multi-turn Crescendo runs.
- Gemini 1.5 Pro: 72. Green belt. Solid baseline with noticeable gaps in agentic security.
- Command R+: 70. Green belt. Comparable to Gemini on the overall score, different specific weaknesses.
- Mistral Large: 65. Green belt. The lowest score in the Green band.
- Llama 3 70B: 58. Orange belt. The large parameter count does not translate to higher resilience on the current control set.
The reference leaderboard is transparent. The scoring methodology is published, the test matrix is published, and the scores are updated when new model versions are released. These are DojoLM numbers, from the DojoLM evaluation, against the current pattern set. Other evaluations will produce different numbers, and that is fine, the methodology is what is worth defending.
Why a Belt Is More Useful Than a Percentage
A percentage says "90% resilient." It sounds fine. It tells nothing about what to do next.
A belt says "Brown, close to Black." It tells three things at once. Where the model stands today. What the next rank requires. And what the culture around the model should be.
Brown belt models can ship to production. White belt models cannot. Green belt models need a guardrail. Blue belt models need a stricter guard profile. No committee is needed to decide any of this. The rubric is public, the placement is public, and the decision is mechanical.
The belt system removes a category of argument from the team's daily work. Instead of "is this model safe enough to ship?" the conversation becomes "this model is Brown belt, and the intended workload is in the Brown belt acceptable range, so it ships." Or "this model is Green belt, and the intended workload is a Brown-and-above workload, so either upgrade the model or re-scope the workload."
Both of those are actionable conversations that finish in ten minutes. "Is this model safe enough?" is a conversation that runs for weeks and never finishes.
The Dojo Culture
If there is one reframe in this whole series, it is this. AI security stops being a scan run before launch. A scan is a snapshot. It ages. It tells nothing about the next model or the next attack. A scan is the thing teams do right before they stop thinking about security.
AI security becomes a dojo. A place where models train, get measured, earn ranks, get retested, and keep improving. Where new attack techniques land, get added to the library, and get tested against every model on the fleet automatically. Where the researchers, the red team, the guardrail owners, and the compliance team all look at the same scoreboard.
A dojo has four cultural properties that a one-time scan does not.
Progression
Models do not just pass or fail. They earn a rank, and they can train to earn a higher rank. The work is continuous, and the work compounds. A model that is Blue belt today can be Brown belt next month if the team closes the gaps that are holding it back. A model that is Brown belt today can lose the rank if a new attack class lands that it cannot defend against.
Progression is not a metaphor. It is the literal data structure the platform uses to talk about models. Belt changes are events in the audit log. A model gaining or losing a belt is a first-class event.
Measurement
Every training session is measured. Every measurement is comparable over time. The scoreboard is the shared language of the team.
The measurement discipline is what keeps the dojo honest. A team that measures itself constantly cannot lie to itself. A team that only measures itself on release day can lie to itself all the other days.
Discipline
The training sessions are not one-off events. They are scheduled, expected, and respected. A dojo that only trains when there is an incident is not a dojo, it is a crisis room. Scheduled sessions are the thing that distinguishes a training practice from a reaction to problems.
This is why Sengoku's Temporal tab matters as much as Sengoku's Workbench. The Workbench runs a campaign. The Temporal tab runs a practice. Practice is what compounds. Campaigns that happen when someone has time do not compound.
Community
The researchers, the red team, and the guardrail owners all work in the same space on the same spine. They are not siloed. A finding from one surfaces immediately for the others. The scoreboard is the shared language, and the shared language is what makes cross-team work possible without meetings.
A researcher who lands a bounty finding knows that the finding will flow into the fixture library, the scanner, the guard, and the compliance dashboard without any additional work. The guardrail owner knows that a new pattern will land in their inline defense without requiring a deploy. The compliance lead knows that a new scanner pattern will update the framework evidence chain automatically. Everyone works on the same spine.
DojoLM is the tooling layer that makes a dojo culture possible without requiring heroic effort. The platform provides the scoreboard, the fixture library, the runtime guard, the compliance map, the research workspace, and the bug bounty pipeline. The team provides the discipline.
Two Weeks of Numbers
Here is the full running total of everything shown across 14 days, all from the live instance.
- Top scored model: 90 (Llama 3.1, Brown belt)
- 13 detection engines, all active
- 1,396 detection patterns across 198 pattern groups
- 2,380 curated attack fixtures across 35 categories
- 7 Atemi Lab workspaces
- 17 active attack tools
- 4 Atemi Lab attack modes (Passive, Basic, Advanced, Aggressive)
- 4 Hattori Guard modes (Shinobi, Samurai, Sensei, Hattori)
- 250 guard events, 127 blocks issued, Samurai mode default
- 27 compliance frameworks mapped
- 69 overall compliance score, 82% OWASP LLM Top 10
- 25 DojoV2 testing-area controls (TA-01 to TA-25) as the spine
- 142 SAGE generations, 0.94 fitness, 1,247 seeds, 23 quarantined
- 6 Amaterasu DNA families, 8 clusters (schema and views shipped, graph being seeded)
- 20 Sengoku temporal plans, 5 orchestrators (Crescendo, PAIR, TAP, MAD-MAX, Sensei-Adaptive)
- 14 target languages across 6 scripts
- 12 bug bounty programs in Ronin Hub
- 24 Kotoba rules, 5 score categories (boundary clarity, instruction priority, role definition, output constraints, injection resistance)
- 107 Kagami signatures in the fingerprint library
- 7 Jutsu belts across a 6 model configured fleet (3 benchmarked, 3 in queue)
- 1,236 test executions logged
- All subsystems healthy, everything running on Voyager, local inference, no cloud round trips
Every number is real. Every number came from the live production instance. Every number is the output of a shared spine that all the modules read from.
The Stack, One Last Time
For the readers who came for the architecture.
- Application. Next.js 16, React 19, Tailwind CSS 4, shadcn/ui components, dark theme
- Detection pipeline. TypeScript, 13 engine modules, shared verdict schema
- Fixture library. 2,380 fixtures as structured YAML/JSON, curated by hand and tagged before they land
- Runtime guard. Hattori Guard, four modes, inline scanner integration
- Research workspace. The Kumite, six subsystems, shared with the scanner
- Compliance. The Bushido Book, 27 frameworks, live evidence links
- Bounty pipeline. Ronin Hub, four tabs, full Armory integration
- Hardware. Voyager, local rack-mounted GPU box
- Models under test. Llama 3.1, Qwen 2.5, Gemma 3, Gemma 3 4B, Llama 3.2 3B, Qwen3 VL 8B (6 configured, 3 fully benchmarked, 3 in queue)
- Audit. Full audit trail on every scan, block, score change, and pattern contribution
- Deployment. Docker Compose on Voyager, single-command deploy from source
What Comes Next, After the Series
The build has been in public for two weeks. What comes next is a continuation of the same discipline.
More patterns in the scanner. More fixtures in the Armory. More SAGE generations. More languages in the multilingual coverage matrix. More bounty programs tracked in Ronin Hub. More DNA clusters identified. More compliance frameworks mapped as new regulations land. A deeper Atemi Lab tool library. A tighter Kagami mirror suite. A faster scanner. A richer Jutsu rubric.
The platform is not done. A platform like this is never done, because the arms race is never done. What exists today is a system that compounds, a team that uses it daily, and a scoreboard that says where the fleet stands. That is the dojo.
The Signoff
Thank you for reading this series.
This was a builder's journal. We published it because the community deserves to see what a production AI security stack actually looks like, rather than the sanitized version that lives in vendor decks or the narrow version that lives in academic papers. Everything in these 14 posts is a real number from a live production instance on dedicated hardware. Everything is running right now.
If you are shipping an LLM product and do not currently have a scoreboard, start there. Not with DojoLM, necessarily. Start by writing down the questions a scoreboard would need to answer. Then ask whether the current tooling answers them. Then start building the answers. The work compounds, the library compounds, the team compounds, and the conversations change.
That is the work. That is the dojo.
See you in the next series.