The Scoreboard: A Builder's Introduction to DojoLM
Most teams shipping LLM products do not have a scoreboard. They have a scan run once before launch and a vendor PDF that nobody reads. DojoLM is a real one: 13 engines, 1,396 patterns across 198 groups, 2,380 fixtures, 25 DojoV2 controls, and a resilience score that moves when the arms race moves. Day 1 of a 14-day builder's journal.

AI security is not broken. It is maturing as fast as it possibly can inside an arms race, and most teams shipping LLM products do not have a scoreboard to know where they stand.
Every week a new class of attack lands in the wild. Prompt injection variants. Jailbreak mutations. Tool-use abuse. MCP exploits. Agent-to-agent compromise. Vector store poisoning. Supply chain drift. Every week the defenders ship a new class of response. Pattern libraries grow. Scanners improve. Guardrails get smarter. Benchmarks get harder.
"A scan ran three months ago and the report said everything was fine."
"A vendor tool got bought. It generates a PDF. The PDF got filed."
"There is a red team checklist in a Notion page. Someone updates it when they remember."
"Model updates ship weekly. Security retests do not happen between releases, the full scan takes two days."
"Nobody has any idea how the new fine-tune compares to the last one on prompt injection."
These conversations happen with engineering leaders at companies shipping production LLM products, and the pattern repeats. The honest question is not is AI security ready? It is where does this team stand this quarter, on this model, on this workload? That is a measurement problem. And most teams are measuring it the same way they would measure uptime with a printed-out Excel sheet.
That is expensive. That is dangerous. That is where DojoLM came from.
The Measurement Problem in AI Security
DojoLM was built over the last year because the existing toolchain forced a choice that should not exist: either run a deep scan once and pretend the result stays valid, or run a shallow scan continuously and pretend the result means anything. Neither is true. The attack surface moves every week. The models move every week. The detection library has to move with both.
What is actually needed is a scoreboard. Something that answers the same questions an engineering leader asks every Monday: what shipped, what broke, what got better, what got worse, what is holding the score back. Something an auditor can read in the same language a developer reads it. Something a product team can make tradeoff decisions against without guessing.
That is not a scanner. That is infrastructure.
What DojoLM Is
DojoLM is a production AI security testing platform. It measures how resilient a language model is against the current attack surface, end to end, on local hardware. Not a framework. Not a wrapper. Not a benchmark suite. A full stack with 13 detection engines, 1,396 detection patterns across 198 pattern groups, 2,380 attack fixtures, 25 DojoV2 controls, and a scoring system that tells the operator where each model on the fleet actually stands this week.
DojoLM runs on Voyager, a local inference node on a private rack, with 6 configured production models under continuous test: Llama 3.1, Qwen 2.5, Gemma 3, Gemma 3 4B, Llama 3.2 3B, and Qwen3 VL 8B. Three are fully benchmarked. Three are still in queue. Nothing leaves the machine. Every number in this post comes from the live instance.
The numbers
- 13 detection engines running in parallel over every payload, each specialized for a class of attack, each reporting independently
- 1,396 detection patterns distributed across the 13 engines (198 pattern groups), every pattern with a category, a severity, a test fixture, and a regression test
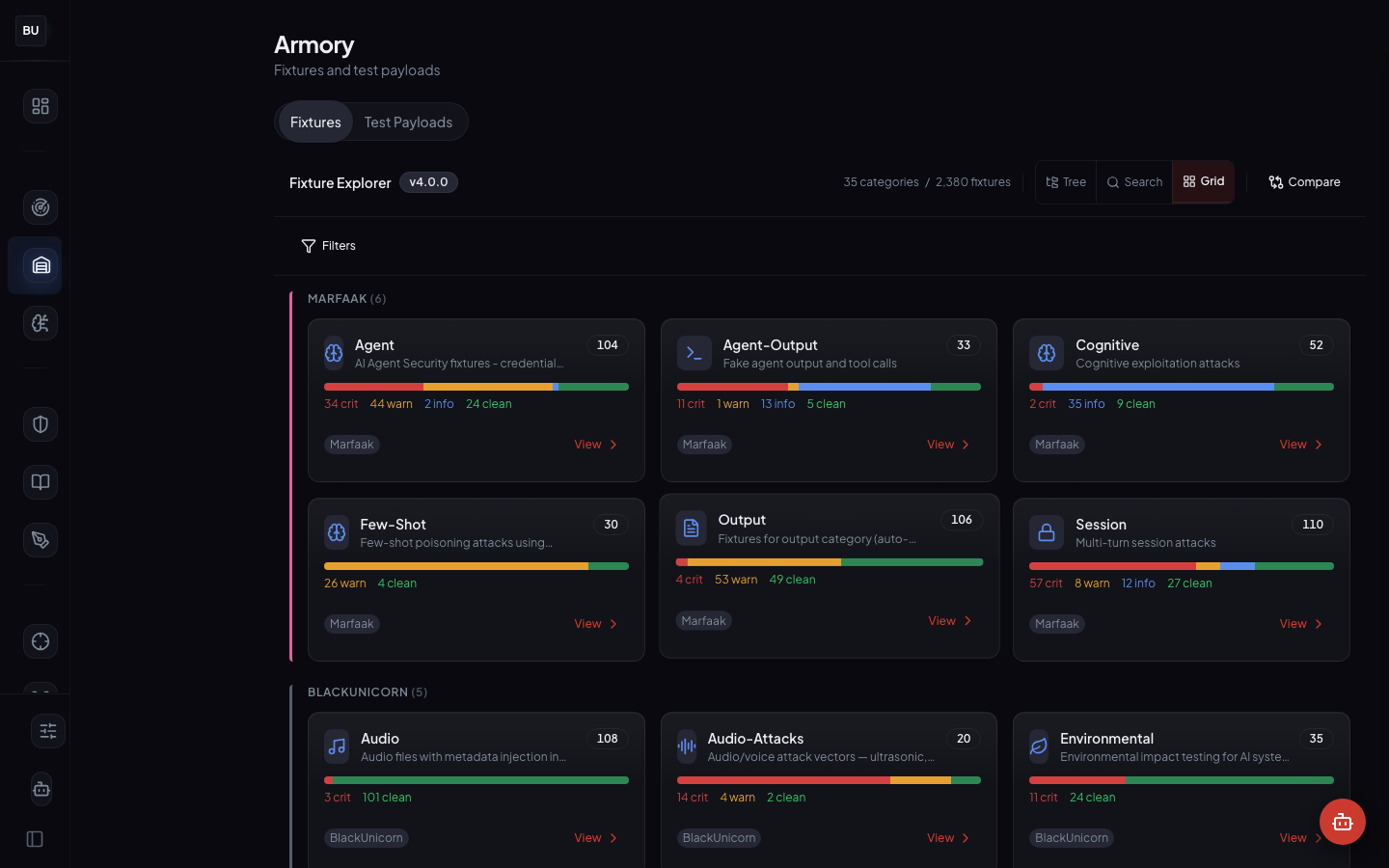
- 2,380 attack fixtures in the Armory, curated by hand and tagged before they land in the library
- 35 fixture categories mapped onto the 13 engines plus cross-cutting concerns
- 25 DojoV2 controls as the master testing-area set (TA-01 through TA-25) the whole platform is measured against
- 27 compliance frameworks mapped to the 25 controls, including OWASP LLM Top 10, NIST AI RMF, ISO 42001, ISO 27001, and the EU AI Act
- 6 production models configured on Voyager, with full per-model scoring on the 3 that are benchmarked
- 1,236 test executions logged across the fleet, every execution tied to a pattern id, a fixture id, and a per-engine verdict
- Hattori Guard in Samurai mode (the demo default), 250 guard events processed, 127 blocks issued, full audit log with pattern attribution on every block
- Top scored model: 90 (Llama 3.1, Brown belt), the leader of the configured fleet
- All subsystems healthy, every module reporting green
This is not theoretical. It is running right now.
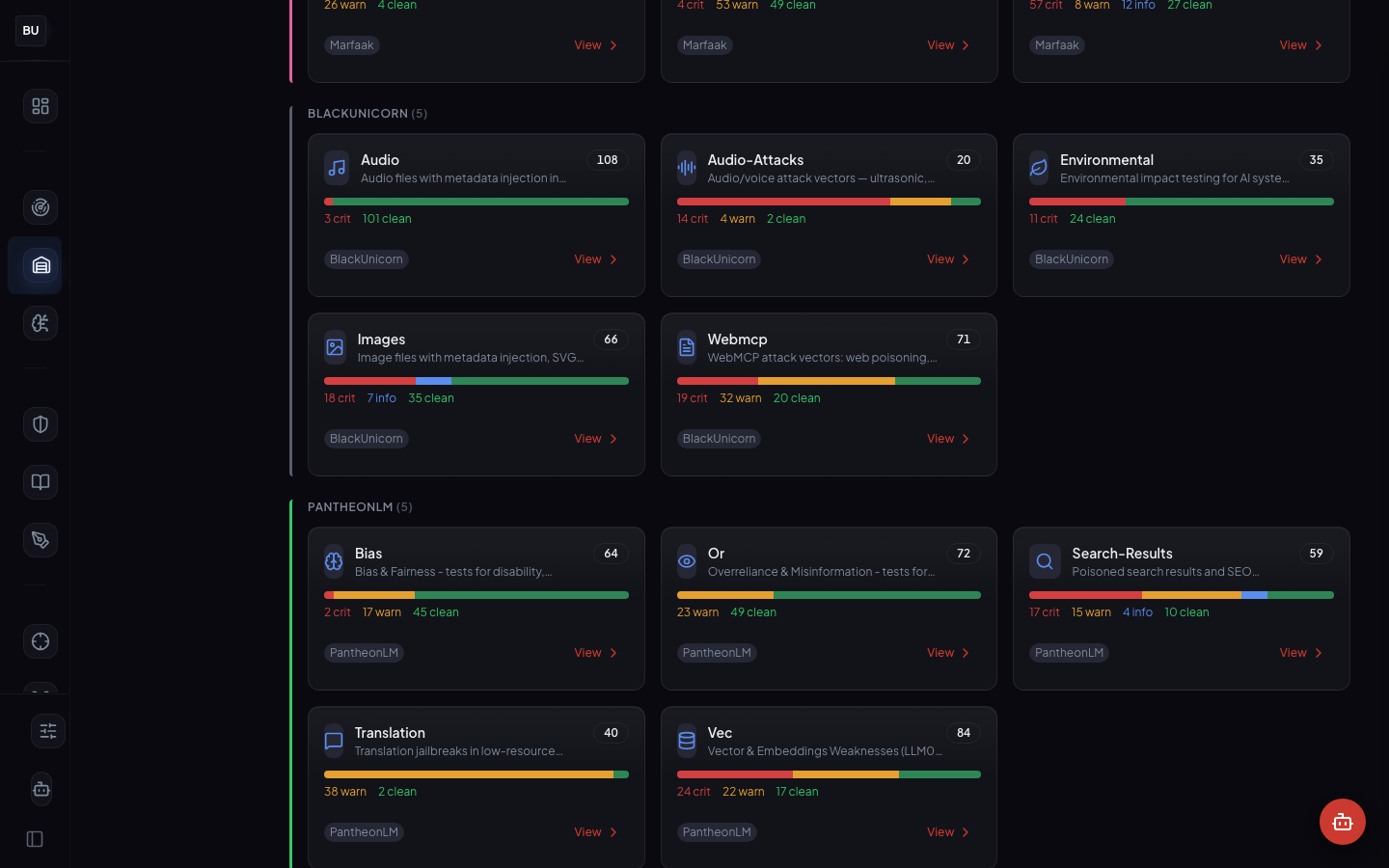
The Current State of the Scoreboard
Here is what the production Dashboard shows this week, read left to right.
Top scored model: 90 (Llama 3.1, Brown belt). That is the highest score across the configured fleet. The 90 is a real number with a real derivation: 25 DojoV2 controls, 13 engines, 1,396 patterns. It opens on the platform with the per-model breakdown, the controls that are passing, the ones holding the score back, and the engines that drove the last delta.
13 of 13 detection engines active. Every engine in the scanner pipeline is live and reporting. No degraded state. No gray zones. When an engine goes experimental or deprecated, the scoreboard labels it and removes it from the scoring weight until it is promoted or retired.
1,236 test executions logged across the configured models. These are not dry runs. Every execution is tied to a pattern id, a fixture id, and a per-engine verdict. The same fixtures run against the same models on every scanner release, which is what makes the score comparable week over week.
Hattori Guard: Samurai mode, 250 events, 127 blocks. The inline runtime guard runs in Samurai mode by default, blocking high-severity attacks while letting lower-severity findings log for review. The block rate sits in the target range. Higher and the guard is over-blocking. Lower and it is missing real attacks. The team treats the guard as a partner, not an obstacle, because every block carries an explanation.
All subsystems healthy. Every module reports green. When something goes yellow, the dashboard names the subsystem and the test that failed, not just "degraded."
Why a Scoreboard Changes the Conversation
A scoreboard changes three things at once. None of them are technical. All of them are operational.
It makes the arms race legible
When a new attack class lands, exposure is no longer a guess. The relevant patterns get added to the scanner, the full fixture bank reruns against every model on the fleet, the new score is compared to last week's score, and the answer is in by the end of the day. The arms race stops being a vibe and starts being a delta.
In practice. Last month a new class of indirect prompt injection landed in one of the tool-use engines. Four new patterns and matching fixtures landed in the scanner. The bank reran. The configured models took a measurable hit on the relevant control. Total time from "the attack is visible" to "the blast radius is known" was 6 hours, not 6 weeks.
It forces honesty about tradeoffs
A faster model with a lower resilience score is a product decision, not a security decision. The scoreboard lets the product team make that decision with its eyes open. "Shipping the faster model because the delta is acceptable for this workload" is a much better conversation than "shipping this model and hoping for the best."
This is the part that was unexpected. When the number is real and visible, the argument stops being "is security important?" and starts being "what is the acceptable score for this product?" That is a much healthier argument. It has an answer. The answer can be written down. The answer can be revisited when conditions change.
It turns security into a shipping discipline
Every model change, every prompt rewrite, every new tool in an agent's toolbox is a hypothesis about resilience. The scoreboard is the test. Security stops being a blocker at the end of the pipeline and starts being a continuous signal during development. The team that rewrites a system prompt can see the score change before lunch. The team that adds a new function to an agent can see which engine fired on their new tool call.
Most organizations treat security as an approval step. The scoreboard treats it as telemetry. The difference is enormous. Approvals slow shipping. Telemetry speeds it up, because the feedback loop is short enough that the team owns the signal instead of waiting for a gate to open.
The 13 Engines, in One Paragraph
The Haiku Scanner is the detection pipeline that every other module sits on top of. It runs every payload through 13 independent detection engines in parallel: Prompt Injection, Jailbreak, Tool-use and Plugin Injection, DoS, Supply Chain, Agent Security, Model Theft, Output Handling, Vector and Embeddings, Overreliance, Bias and Fairness, Multimodal Security, and Environmental Impact. Each engine ships with its own pattern library, its own regression suite, and its own maintainer. Each engine returns a structured verdict with a boolean hit, a matched pattern id, a severity level, and a confidence. The verdicts are aggregated into an overall score, but the per-engine breakdown is preserved on every result, which is the basis of explainability. Day 2 is the full scanner deep dive.
The 2,380 Fixtures, in One Paragraph
The Armory is the fixture library the scanner is measured against. 2,380 fixtures organized across 35 categories, every fixture with a severity, a category, a pattern id, and a reproducible payload. Curated by hand. Never scraped. Provenance is first class. Every fixture is a regression test for the scanner, which means every pattern in the scanner has at least one fixture that exercises it. New patterns ship with new fixtures. New fixtures ship with verification that they exercise a pattern. The two artifacts are always in sync. Day 3 is the Armory tour.
The 25 DojoV2 Controls and the Spine of the Platform
DojoV2 is the control set the whole platform is measured against. Think of it as the spine. Every engine, every fixture, every rule, every compliance claim maps back to one or more of the 25 testing-area controls (TA-01 through TA-25). When the scoreboard shows the leader at 90, it is the weighted average of 25 control-level scores for that model. When a control drops, the dashboard surfaces exactly which engine and which fixture drove the drop. When an auditor asks "how do you know you cover output handling risk?" the answer is a control id, a list of engines, a count of fixtures, and a test log.
The Bushido Book (Day 6) translates those 25 controls into 27 compliance framework dialects: OWASP LLM Top 10, NIST AI RMF, ISO 42001, ISO 27001, the EU AI Act, and 22 others. One control set, 27 translations, one source of truth. That is what compliance is supposed to look like in a world where the frameworks are still being written.
The Jutsu Belt System
Sitting on top of the scoreboard is a seven-belt ranking system inspired by martial arts progression: White, Yellow, Orange, Green, Blue, Brown, Black. Every configured model earns a belt based on its resilience score and the consistency of its scores across the 25 controls. The current fleet leader, Llama 3.1, sits at 90, Brown belt.
Belts are not decoration. They are the shorthand the team uses to decide which workloads a given model can take on. Brown belts ship to production with standard guardrails. Blue belts need a stricter guardrail profile and a human-in-the-loop. White belts do not ship at all. Green belts are fine for internal tooling but not for customer-facing work. The belt system removes a category of argument from the team's daily work, because the conversation is no longer "is this model safe enough?" but "what belt is it, and what workloads are cleared for that belt?"
Day 14 closes the series with the full belt scoring methodology and the data from the last six weeks of ranking changes.
The Fleet, by Model
The dashboard shows the current state for the 6 configured models on Voyager. Three are fully benchmarked. Three are still in queue.
- Llama 3.1, resilience 90, Brown belt, fleet leader, cleared for production workloads with standard guardrails
- Qwen 2.5, resilience 83, Blue belt, cleared for production with a stricter guardrail profile
- Gemma 3, resilience 8, White belt, not cleared for deployment
- Gemma 3 4B, pending benchmark
- Llama 3.2 3B, pending benchmark
- Qwen3 VL 8B, pending benchmark
Every belt placement is traceable to a control-level breakdown, which is traceable to an engine-level breakdown, which is traceable to a fixture-level breakdown. When a model drops a belt, the cause is not a guess. The full chain is in the audit log.
The honest framing: production-ready models exist on the fleet, the leader is Brown belt at 90, and the rest of the queue is being benchmarked. The score is not a fleet average. It is a leaderboard.
The Principles Behind the Platform
Measurement before opinion
Every claim DojoLM makes is backed by a fixture, a pattern, and an execution log. The platform does not ship "this is probably safer." It ships "the score went up by 3 points because these 7 patterns are now catching these 22 fixtures they were missing last week." The measurement comes first. The opinion is optional.
Independence is the point
Thirteen independent engines fail in thirteen different ways. A single classifier fails in correlated ways, which is how silent misses happen across a whole class of attacks. The scanner pays an overhead cost for running 13 engines in parallel instead of one. On Voyager, a full scan returns in under a second for most payloads. The cost is worth it, because the alternative is a single point of failure that ages faster than it can be retrained.
Curation, not scraping
The Armory is curated by hand. Every fixture has a maintainer and a provenance. Raw red team output never gets dumped into the library. Jailbreak forums never get scraped. The metadata is the value. A payload without structured metadata is a curiosity, not a test case.
Compliance as a translation layer
The 25 DojoV2 controls are the source of truth. The 27 compliance frameworks are translations. When a new framework lands (and another one will land this quarter, there is always another one), DojoLM adds a translation, not a new control set. The scoreboard does not care which framework an auditor speaks.
Builder's journal, not vendor deck
Everything in this series is a real number from the live instance. No illustrations. No mockups. No marketing renders. Every screenshot is a production screenshot. Every metric is a live metric. If a number in this post does not match the Dashboard, it is a mistake and it will get fixed.
The Stack
A quick technical inventory, for the readers who want to know the shape of the machine.
- Inference node. Voyager, a local rack-mounted GPU box. Everything runs on-prem. Nothing leaves the network.
- Models under test. Llama 3.1, Qwen 2.5, Gemma 3, Gemma 3 4B, Llama 3.2 3B, Qwen3 VL 8B (6 configured, 3 fully benchmarked, 3 in queue)
- Application. Next.js 16, React 19, Tailwind CSS 4, shadcn/ui components, dark theme, fast, designed for operational awareness
- Scanner pipeline. TypeScript, 13 engine modules, shared verdict schema, per-engine maintainer ownership
- Fixture library. 2,380 fixtures as structured YAML and JSON, regression tests on every commit
- Runtime guard. Hattori Guard, four modes (Shinobi, Samurai, Sensei, Hattori), inline scanner integration
- Audit. Full audit trail on every scan, every block, every score change, every pattern contribution. Queryable by time, model, engine, fixture, or pattern id.
- Deployment. Docker Compose on Voyager. Internal hostname
dojo.bucc.internal. Single-command deploy from source.
The stack is not the interesting part. The interesting part is that every piece of it serves one goal: every number on the Dashboard has to be traceable back to a fixture and an engine verdict, because otherwise the scoreboard is a guess, and a guess is what DojoLM was built to replace.
What This Series Covers
The 14-day series walks through every major module of the platform, one module per weekday. Each day has a social post for the short version and a blog deep dive like this one for the architecture.
Week 1. The Scoreboard (today), the Haiku Scanner, the Armory, Atemi Lab, Hattori Guard, the Bushido Book, and the Week 1 platform guide synthesis.
Week 2. The Kumite and SAGE, Amaterasu DNA, Sengoku, multilingual detection, Ronin Hub, Kotoba and Kagami, and the Jutsu belt system with the full series wrap-up.
Here is the order with the provisional URLs, so you can bookmark the ones that matter most to your work.
- Day 1, today. The Scoreboard. Where the platform stands.
/blog/dojo-scoreboard - Day 2. The Haiku Scanner. 13 engines, 1,396 patterns, the reasoning behind a stacked engine architecture.
/blog/haiku-scanner-13-engines - Day 3. The Armory. 2,380 curated fixtures, four views, why curation beats scraping.
/blog/armory-attack-library - Day 4. Atemi Lab. Agent-to-agent attacks, MCP fuzzing, seven workspaces, four attack modes.
/blog/atemi-lab-agent-to-agent - Day 5. Hattori Guard. Shinobi, Samurai, Sensei, Hattori. Four modes, one guard.
/blog/hattori-guard-four-modes - Day 6. The Bushido Book. 27 compliance frameworks mapped to 25 controls.
/blog/bushido-book-29-frameworks - Day 7. Week 1 synthesis. How the six modules fit together.
/blog/dojolm-platform-guide - Day 8. The Kumite and SAGE. Evolved attacks, fitness scoring, champion promotion.
/blog/kumite-sage-battle-arena - Day 9. Amaterasu DNA. Attack lineage, family trees, coverage graphs.
/blog/amaterasu-attack-lineage - Day 10. Sengoku. Automated red team campaigns.
/blog/sengoku-automated-red-team - Day 11. Multilingual detection. 14 languages, 6 scripts.
/blog/multilingual-attack-detection - Day 12. Ronin Hub. Bug bounty command center.
/blog/ronin-hub-bug-bounty - Day 13. Kotoba and Kagami. The prompt security lifecycle.
/blog/kotoba-kagami-prompt-lifecycle - Day 14. Jutsu belts. Why every team needs a dojo.
/blog/jutsu-belts-every-team-needs-dojo
The Principle Behind Publishing This
This series is published because the community deserves to see what a production AI security stack actually looks like. Most of what is out there is either a vendor deck or an academic paper. The first tells you what a platform promises. The second tells you what a narrow technique achieves in a lab. Neither tells you what it looks like when all of the pieces have to work together, every day, against a moving target, on real hardware with real budgets and a team that has other jobs.
This is a builder's journal. The work gets shown.
If you are shipping an LLM product and do not currently have a scoreboard, start there. Not with DojoLM, necessarily. Start by writing down the questions you would want your scoreboard to answer. Then ask whether your current tooling answers them. Then ask what it would take to close the gap.
That is the work.
Tomorrow, Day 2, the Haiku Scanner opens up. 13 engines, 1,396 patterns, one pipeline, and the reasoning behind why a stacked engine architecture beats a single classifier on every axis that matters.
See you there.