The Bushido Book: 27 Compliance Frameworks, One Spine
Compliance is usually where AI security conversations go to die. The frameworks multiply, the vocabulary diverges, and a team shipping internationally ends up mapping a single technical control across a half-dozen regimes at once. The Bushido Book is the map. 27 frameworks, 25 DojoV2 controls (TA-01 through TA-25), 69 overall score, live evidence links, and a Gap Matrix that tells you exactly where the holes are. Day 6 of the DojoLM builder's journal.

Compliance is usually where AI security conversations go to die. The frameworks multiply, the vocabulary diverges, and a team shipping confidently on Friday spends all of Monday rewriting control language to satisfy three different auditors.
"There is a spreadsheet mapping the controls to OWASP. Nobody trusts it anymore."
"Procurement sent a 200-line AI security questionnaire last week. It has not been answered yet."
"The security team wrote up a NIST AI RMF posture six months ago. The platform has changed since then."
"The company is in the EU. An AI Act readiness statement will be needed by the end of the quarter. There is no plan for how to produce one."
"Compliance and engineering do not talk to each other. The compliance team owns a document that the engineering team has never read."
The problem is not that the frameworks disagree. The problem is that they are describing the same underlying controls in different dialects, and there is no common map. Teams end up building the map themselves, in a spreadsheet, over and over. Every team redoes the work. Every spreadsheet goes stale the week after it is written.
The Bushido Book is the map, built once and maintained inside the platform.
What the Bushido Book Is
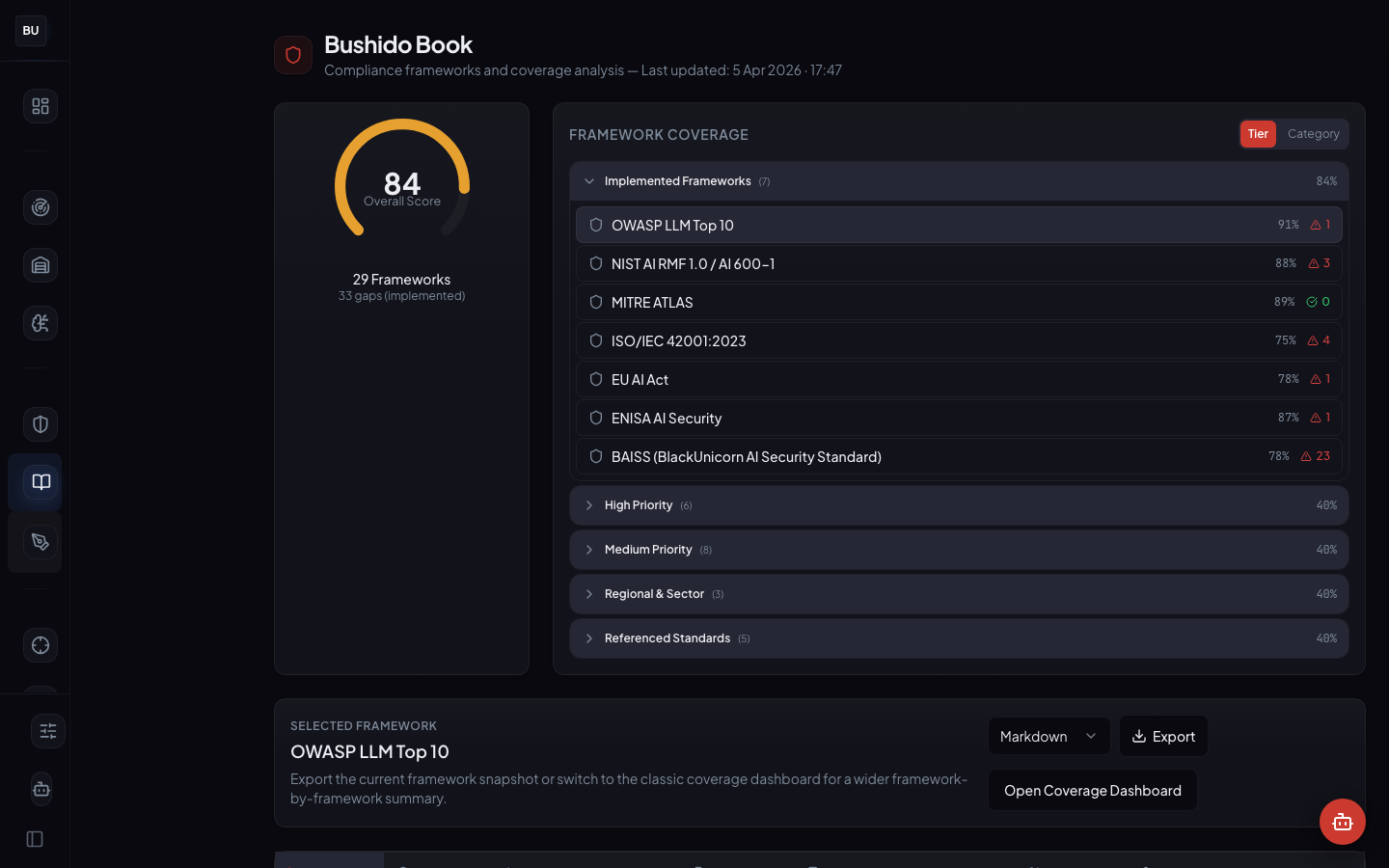
The Bushido Book is DojoLM's compliance workspace. It takes the 25 DojoV2 controls (the same testing-area controls that feed the resilience scoreboard) and maps them against 27 frameworks. Every control has a status, a source of evidence, a severity, and a gap indicator. Every cell in the matrix points at a concrete platform artifact, not a document claiming the control is implemented.
Production state: 27 frameworks mapped, 69 overall compliance score (averaged across demo framework scores), OWASP LLM Top 10 at 82%, several frameworks fully implemented with evidence linked, Gap Matrix view live.
The numbers
- 27 frameworks mapped against the DojoV2 control set
- 25 DojoV2 controls (TA-01 through TA-25) as the single source of truth
- 69 overall compliance score, weighted across frameworks
- 82% OWASP LLM Top 10 coverage, the highest-scoring framework on the demo instance
- Gap Matrix view showing cross-framework control coverage
- Live evidence links from every mapped control to a scanner pattern, fixture, guard log entry, Kotoba rule, or Sengoku campaign result
- Automatic rot detection, if an evidence artifact disappears, the framework entry turns red
The compliance score is not a document. It is a readout of the live platform.
The 27 Frameworks
The mapped framework list covers the major AI governance regimes plus the general security frameworks that AI controls have to fit into.
AI-specific frameworks. OWASP LLM Top 10, NIST AI RMF, ISO 42001, MITRE ATLAS, the EU AI Act, the UK AI Safety Institute guidelines, Singapore's AI Verify, Japan's AI Governance Guidelines.
General security frameworks with AI applicability. ISO 27001, SOC 2 (with the AI addendum), NIST CSF 2.0, CIS Controls.
Sector-specific frameworks. HIPAA (for healthcare deployments), PCI DSS (for payment contexts), GDPR and CCPA (for data handling), FINRA and SEC guidance (for financial services), FedRAMP (for government work).
Emerging and regional frameworks. China's TC260 guidelines, Canada's AIDA (when it lands), Brazil's AI bill (when it lands), the Bletchley Declaration signatory commitments.
Every framework is a translation layer. It maps a DojoV2 control into the framework's vocabulary and the framework's expected evidence format. A single control in DojoV2 may map to one control in OWASP, two sub-controls in NIST, a section reference in the EU AI Act, and a policy statement in ISO 42001. The Bushido Book tracks all of those mappings in one place and updates them whenever the underlying artifacts change.
Principles Behind the Map
One control set, many dialects
DojoV2 is the ground truth. 25 testing-area controls, maintained by the DojoLM team, updated as the platform evolves. Each framework is a translation layer that maps DojoV2 into the framework's own vocabulary. When a new framework lands (and another one always lands), the Bushido Book adds a translation, it does not rebuild the control set. This is the principle that keeps the map from collapsing under its own weight.
The alternative is what most organizations end up with: a separate control set per framework, duplicated evidence, inconsistent language, and a team that cannot answer the question "are we covered for this attack class?" without three different documents.
Evidence, not attestation
Every mapped control points at a concrete artifact. A scanner pattern id. An Armory fixture id. A Hattori Guard log entry. A Kotoba rule. A Sengoku campaign result. The evidence is not a document claiming the control is implemented. It is a live link to the platform artifact that implements it.
If the evidence disappears (a pattern gets removed, a fixture gets deprecated, a Kotoba rule gets archived), the framework entry turns red automatically. Compliance evidence cannot rot silently, because the rot is visible. A compliance dashboard that cannot detect its own rot is a document, not a dashboard.
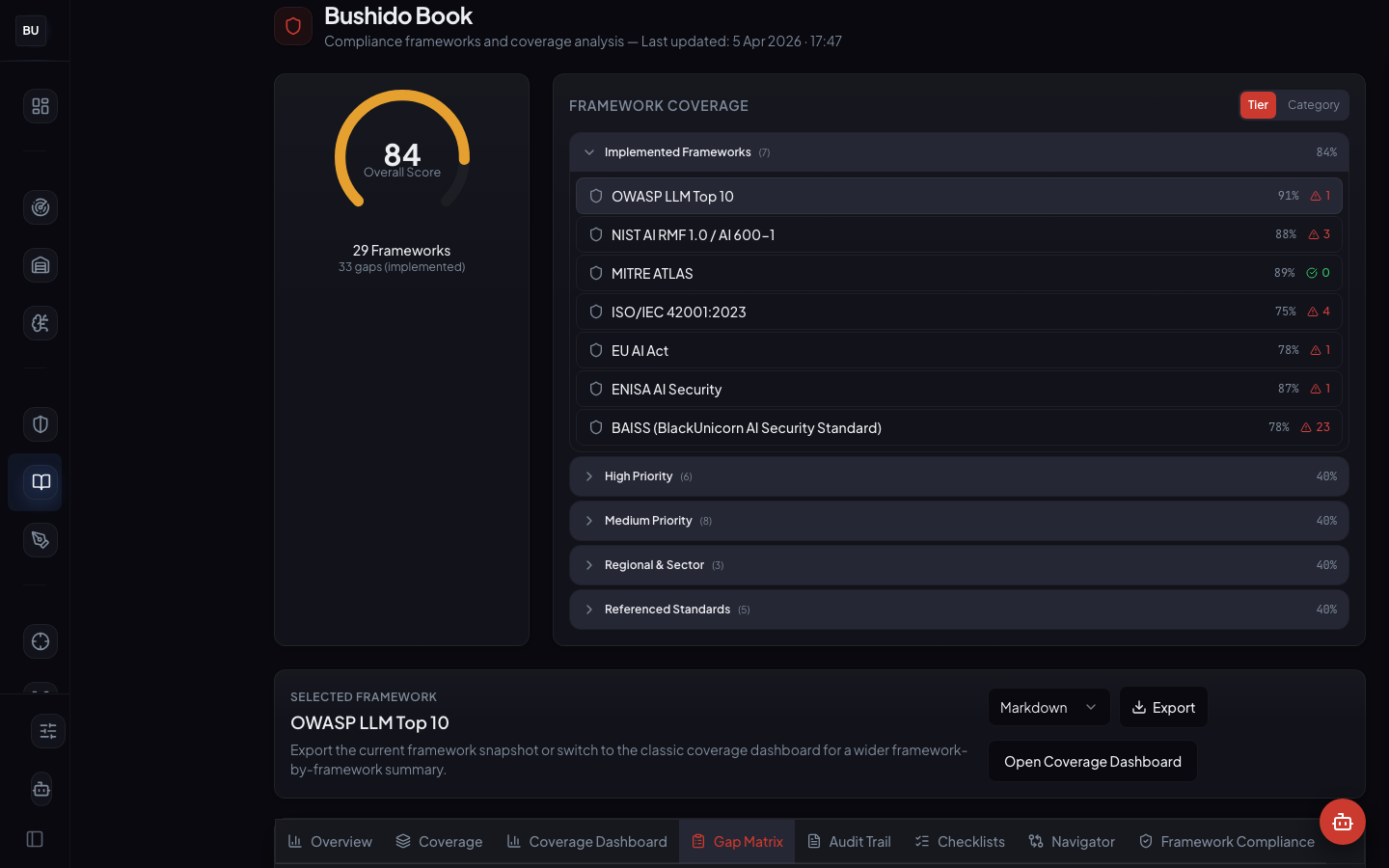
Gap matrix first
The Gap Matrix is the page auditors and security leads actually use. It shows which controls are satisfied by one framework but not another, so the delta can be closed on purpose instead of by accident. A control that satisfies OWASP but not NIST is a known gap that can be worked to close, rather than a surprise discovered three days before an audit.
The matrix is two-dimensional. Frameworks on one axis, controls on the other. Every cell is either green (satisfied with linked evidence), amber (partial), red (gap), or gray (not applicable to this framework). The overall 69 score is the weighted average of green cells.
Scoring you can defend
The 69 overall score is a weighted average with visible weights. Anyone can open the scoring methodology, see how each framework contributes, see how each control is weighted within each framework, and argue with the weights. Hidden scoring is not scoring. It is a number someone made up that happens to correlate with how much the vendor wants the reader to feel good.
When an auditor asks "why is the score 69?" the answer is "here is the methodology file, here are the framework weights, here are the control weights within each framework, and here are the cells that are not green yet." The auditor can read the methodology in ten minutes.
Compliance and security share a spine
The Bushido Book does not maintain its own separate evaluation pipeline. It reads directly from the same engines, fixtures, and rules that power the rest of the platform. A regression caught by the Haiku Scanner on Monday shows up in the compliance dashboard by Tuesday without anyone having to re-enter the finding.
This is how compliance stops being a documentation exercise and starts being a live property of the system. When the scanner gets better, the compliance score gets better. When a pattern gets deprecated without a replacement, the compliance score gets worse. The score is connected to the reality of the platform, not to whether someone remembered to update a document.
The DojoV2 Control Set
DojoV2 is the internal control taxonomy the platform is built around. 25 testing-area controls (TA-01 through TA-25) covering the full attack and defense surface:
- Input validation (patterns against prompt injection, jailbreak, and encoding bypasses)
- Output handling (XSS, SSRF, and script injection in model output)
- Agent safety (tool-use, chaining, and MCP boundary controls)
- Tool use (argument fuzzing defense, schema protection)
- Model selection (belt-based workload clearance)
- Prompt hardening (Kotoba rule enforcement)
- Runtime enforcement (Hattori Guard mode discipline)
- Audit logging (full trail with pattern attribution)
- Incident response (the disclosure lifecycle via Ronin Hub)
- Multilingual coverage (14 languages across 6 scripts)
- Bias monitoring (the Bias and Fairness engine)
- Hallucination handling (the Overreliance engine plus Kagami fingerprinting)
- Data handling (PII and credential detection)
- Supply chain verification (model provenance checks)
- Evaluation cadence (continuous scanner regression against the fleet)
- Red team cadence (the Kumite and Sengoku runs)
- Disclosure handling (coordinated disclosure through Ronin Hub)
- Drift detection (week-over-week scoreboard comparison)
Plus additional testing-area controls covering multimodal surfaces, protocol-level probes, and fleet-wide regression cadence. Every engine in the Haiku Scanner maps to one or more DojoV2 controls. Every fixture in the Armory exercises one or more controls. Every Hattori Guard mode is a specific enforcement posture for a chosen subset of controls. Every framework in the Bushido Book is a translation of DojoV2 into a different dialect.
The Gap Matrix, Worked Example
Imagine a cell that is green for OWASP LLM Top 10 and red for ISO 42001. What does that mean?
It means the DojoV2 control that satisfies OWASP's specific expectation (say, output encoding for downstream consumers) is implemented and linked to evidence. But the broader ISO 42001 expectation around it (say, AI output governance documentation and a policy statement on output handling) is not yet covered by a linked evidence artifact. The gap is not that the technical control is missing. The gap is that ISO 42001 expects an additional documentation artifact that the current evidence chain does not capture.
The Gap Matrix highlights this difference. A compliance lead can read it and assign work. An engineer can link a new artifact (maybe a document published under the Bushido Book's evidence repository) to close the gap. Both know exactly what is missing and what "done" looks like.
The inverse case is also useful. A cell that is green for ISO 42001 but red for OWASP means the documentation exists but the technical implementation has an unfinished piece. That is a different kind of gap, and it requires different work.
The 82% OWASP State, Explained
OWASP LLM Top 10 at 82% is the highest framework score on the demo instance. That is not because OWASP is easier than the other frameworks. It is because OWASP's vocabulary is the closest match to DojoV2, so the translation layer is thin and the evidence chains are short. Every OWASP LLM-01 through LLM-10 item maps to specific DojoLM engines and fixtures without a lot of translation overhead.
Other frameworks score lower not because their technical controls are missing but because their documentation expectations are deeper. ISO 42001 wants policy statements. NIST AI RMF wants risk framing documents. The EU AI Act wants a classification artifact. All of those exist in the platform as evidence repositories, but the work of writing them to the expected depth is ongoing.
The 82 is defensible because the points not yet green are visible on the Gap Matrix with the exact reasons they are not green. Nobody guessing. Nobody gaming the score.
Why This Matters
Most AI teams ship first and discover their compliance gap later, usually when a customer procurement team sends a 200-line questionnaire. The choice at that point is to scramble or to stall the deal. Both options are bad. Scrambling produces a document that does not match reality. Stalling the deal produces a lost customer.
A live compliance map changes that conversation. Answer the questionnaire by opening the Bushido Book, exporting the relevant framework view, and sending a document that points back at real platform evidence. Procurement conversations stop being a surprise and start being a routine export.
The deeper change is cultural. Compliance stops being the thing that happens after engineering. It becomes a live readout of how well the engineering is working. A team that sees the compliance score move in real time starts to care about it the same way they care about the resilience score. Both numbers are signals the team owns, not reports somebody else writes.
What the Frameworks Actually Expect
Every framework has its own expectation format. A quick tour of the top ones and what they want.
OWASP LLM Top 10. Technical controls with pattern-level evidence. Closest match to DojoV2. The Bushido Book exports OWASP evidence as a structured JSON document with pattern ids, fixture counts, and guard log summaries.
NIST AI RMF. Risk-framed language. Every control has to map to a risk category (Govern, Map, Measure, Manage) and include a risk narrative. The Bushido Book generates the narrative from the underlying evidence and surfaces it for review.
ISO 42001. Policy-first. Every control expects a written policy statement, a procedure, and evidence of operation. The Bushido Book maintains a policy repository alongside the evidence chain and links them together.
EU AI Act. Classification-first. Before controls come into view, the system's risk classification has to be declared. The Bushido Book supports the classification workflow and generates the technical file structure the Act expects.
ISO 27001. The general security backbone. Most of the AI-specific controls map back to broader ISO 27001 controls around access control, asset management, and incident response. The Bushido Book handles the mapping so teams do not have to maintain two separate systems.
What Is Next
Tomorrow, Day 7, is the Week 1 synthesis. The module tour pauses and shows how the six modules covered so far (Dashboard, Scanner, Armory, Atemi Lab, Guard, Bushido Book) connect into a single platform with a single spine.
The Day 7 deep dive is the full platform guide, the document we wish had existed when we started building DojoLM.
See you there.